NVIDIAs unerlaubtes Scraping von YouTube- und Netflix-Videos zur KI-Trainierung aufgedeckt
Most people like
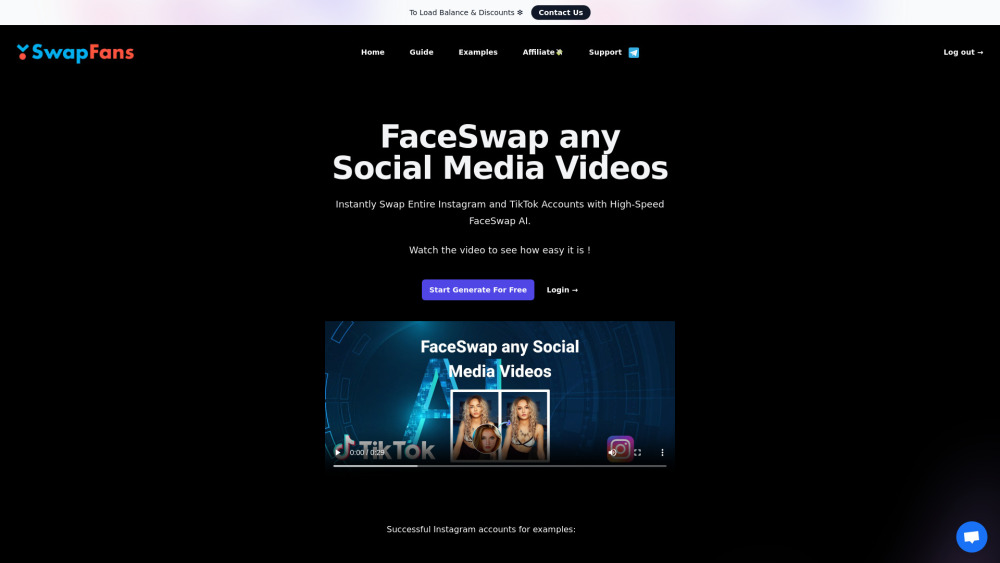
Verwandle Deine Social-Media-Videos mit KI-gestechnter FaceSwap-Technologie
Nutze die Kraft der KI, um Gesichter in Deinen Social-Media-Videos nahtlos zu tauschen. Verbessere Deine Inhalte und fessle Dein Publikum wie nie zuvor mit unserem innovativen FaceSwap-Tool. Entdecke, wie einfach es ist, teilbare, unterhaltsame Videos zu erstellen, die Aufmerksamkeit erregen und die Interaktionen auf verschiedenen Plattformen steigern.
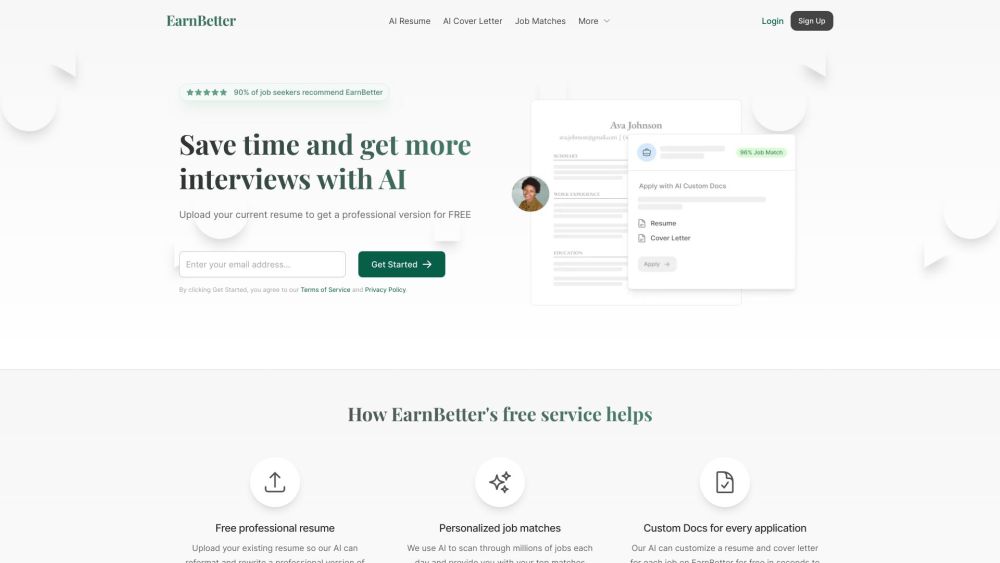
Entfalten Sie Ihr Karrierepotenzial mit unserem kostenlosen KI-Jobassistenten. Dieses innovative Tool optimiert Ihre Jobsuche, indem es personalisierte Empfehlungen, maßgeschneiderte Lebenslaufvorschläge und Tipps zur Interviewvorbereitung bietet. Egal, ob Sie Ihren ersten Job suchen oder einen Karrierewechsel anstreben, unser KI-Assistent wurde entwickelt, um Ihre Jobsuche zu verbessern und Sie mit Möglichkeiten zu verbinden, die zu Ihren Fähigkeiten und Zielen passen. Beginnen Sie noch heute, Ihre Jobsuche zu maximieren!

Entdecken Sie ein KI-Tool, das Ihre Bilder mühelos verbessert und hochskaliert. Verwandeln Sie Ihre Fotos mit modernster Technologie, die Qualität und Detailreichtum steigert, sodass Ihre visuellen Inhalte mit minimalem Aufwand herausstechen. Ideal für Designer, Fotografen oder jeden, der seine Bilder mühelos aufwerten möchte.

In der heutigen, schnelllebigen digitalen Landschaft ist die Optimierung der Leistung entscheidend für Anwendungen, die auf künstlicher Intelligenz basieren. Ein KI-Modell-Lader vereinfacht den Initialisierungsprozess und führt zu erheblich kürzeren Kaltstartzeiten. Dieses innovative Werkzeug sorgt für ein nahtloses Erlebnis, das Entwicklern ermöglicht, die Effizienz zu maximieren und die Benutzerzufriedenheit zu verbessern. Entdecken Sie, wie ein effektiver KI-Modell-Lader die Reaktionsfähigkeit und Leistung Ihrer Anwendung transformieren kann.
Find AI tools in YBX
Related Articles
Refresh Articles