Wichtiger Durchbruch im LLaVA++-Projekt: Verbesserung der visuellen Fähigkeiten der Phi-3- und Llama-3-Modelle
Most people like
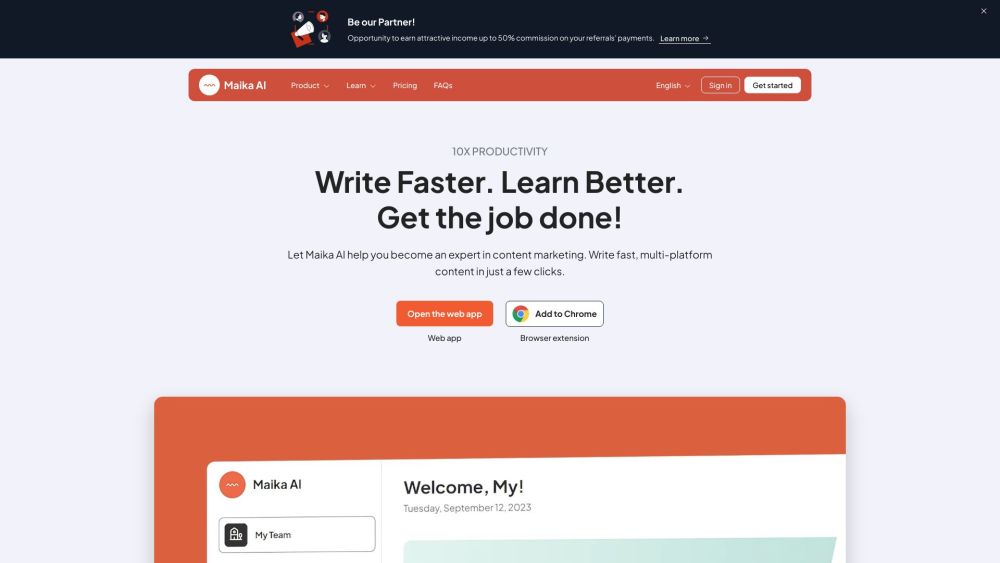
Entdecken Sie das ultimative KI-gestützte Tool zur Inhaltserstellung, das speziell für Marketer und Content-Ersteller entwickelt wurde. Verbessern Sie Ihre Inhaltsstrategie, optimieren Sie Ihren Arbeitsablauf und erreichen Sie Ihr Publikum effektiv mit modernster KI-Technologie. Entfalten Sie Ihr kreatives Potenzial und heben Sie Ihre Marketingkampagnen noch heute auf ein neues Level!
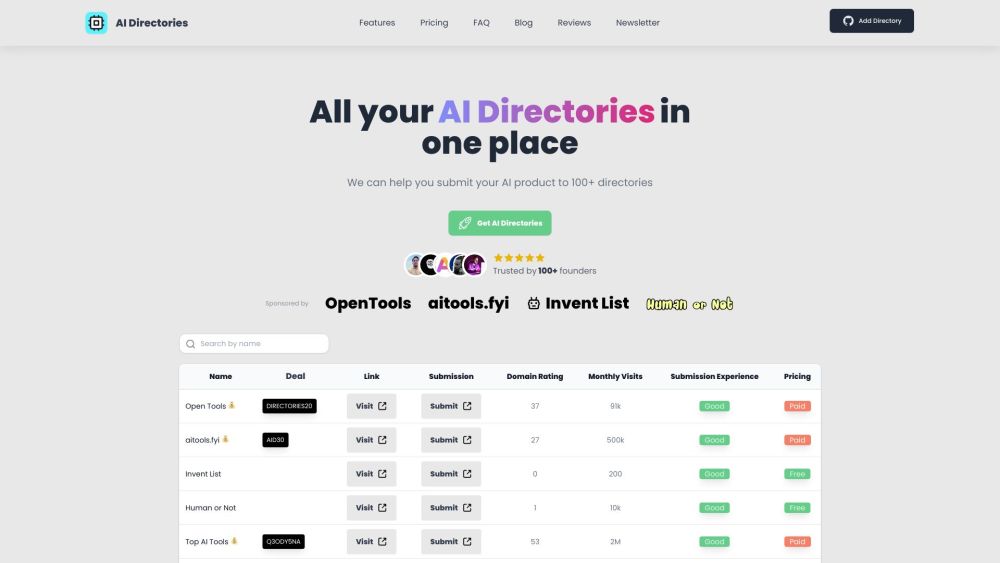
Entdecken Sie unsere sorgfältig ausgewählte Kollektion aus modernen KI-Tools, die darauf ausgelegt sind, Ihre Projekte zu optimieren und Ihre Arbeitsabläufe zu vereinfachen. Von der Inhaltsgenerierung bis zur Datenanalyse bieten Ihnen diese innovativen Ressourcen die Möglichkeit, das volle Potenzial künstlicher Intelligenz auszuschöpfen. Tauchen Sie ein und erkunden Sie die Zukunft der Technologie mit unserer umfassenden Auswahl an erstklassigen KI-Tools!
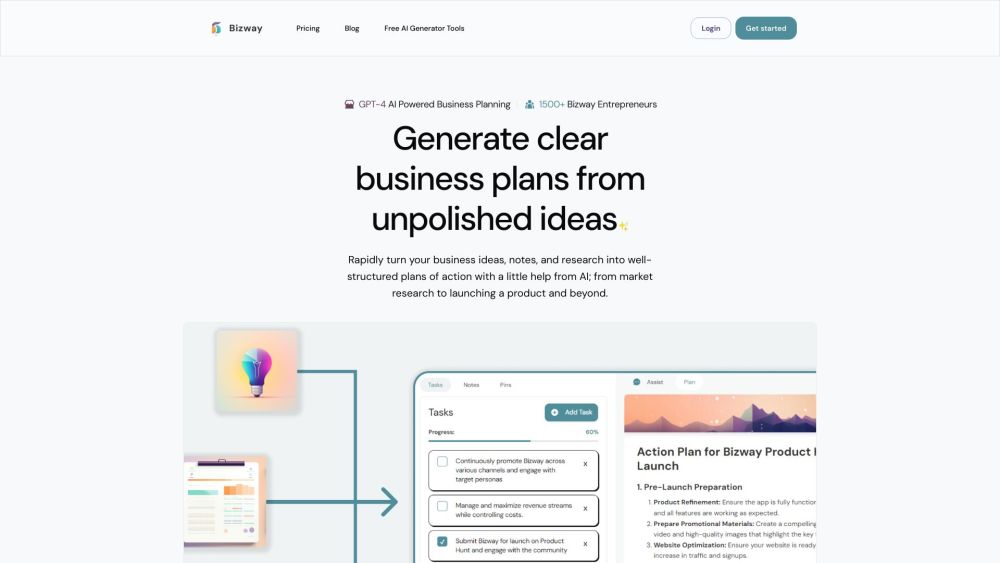
Verwandeln Sie Ihre Ideen in wirkungsvolle Taten mit Bizway. Entdecken Sie, wie unsere innovative Plattform Sie dabei unterstützt, Ihre Visionen zum Leben zu erwecken!
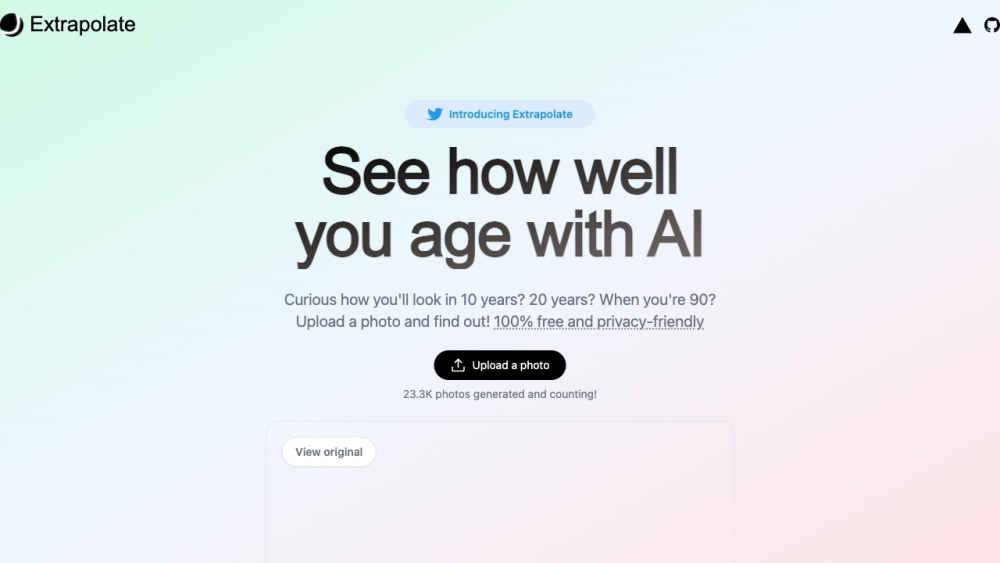
Entdecken Sie, wie die Extrapolate-App fortschrittliche KI-Technologie nutzt, um Ihnen Einblicke in Ihren Alterungsprozess zu geben – dabei wird Ihre Privatsphäre garantiert gewahrt und Ihnen ein völlig kostenloses Erlebnis geboten.
Find AI tools in YBX
Related Articles
Refresh Articles