Apple Aclara: Recursos de YouTube Utilizados para Entrenamiento de IA, No Aplicados a la Inteligencia de Apple
Most people like

Descubre la plataforma todo-en-uno definitiva diseñada para estudiantes, empresas y creadores. Optimiza tu flujo de trabajo y desbloquea tu potencial en un único entorno cohesivo, adaptado para satisfacer diversas necesidades.
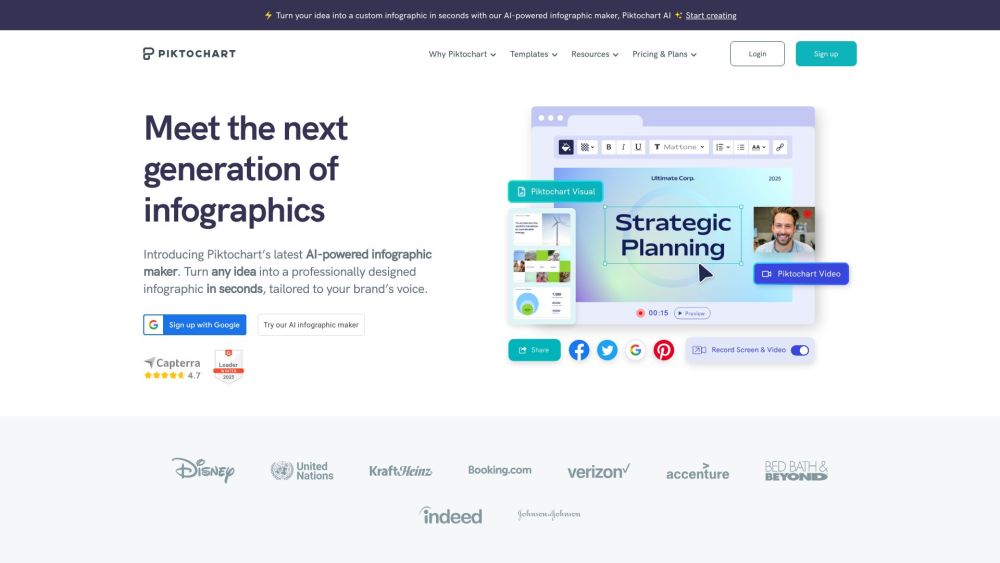
Crea fácilmente infografías y diseños impresionantes sin necesidad de experiencia previa en diseño.
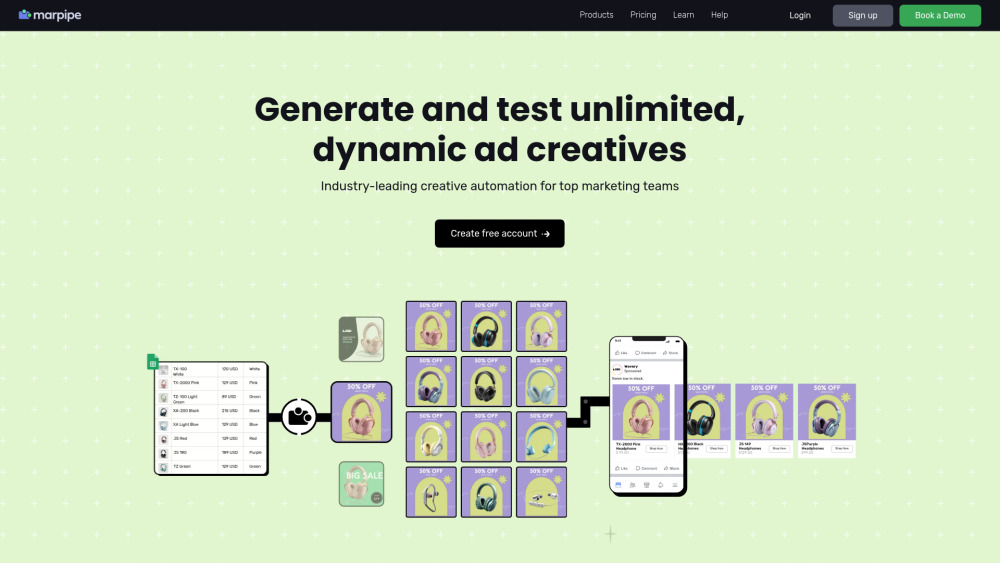
Presentamos una plataforma automatizada diseñada para la creación y prueba de Anuncios de Productos Dinámicos. Optimiza tus esfuerzos publicitarios y mejora el engagement con soluciones personalizadas que optimizan tu estrategia de marketing de manera eficiente.
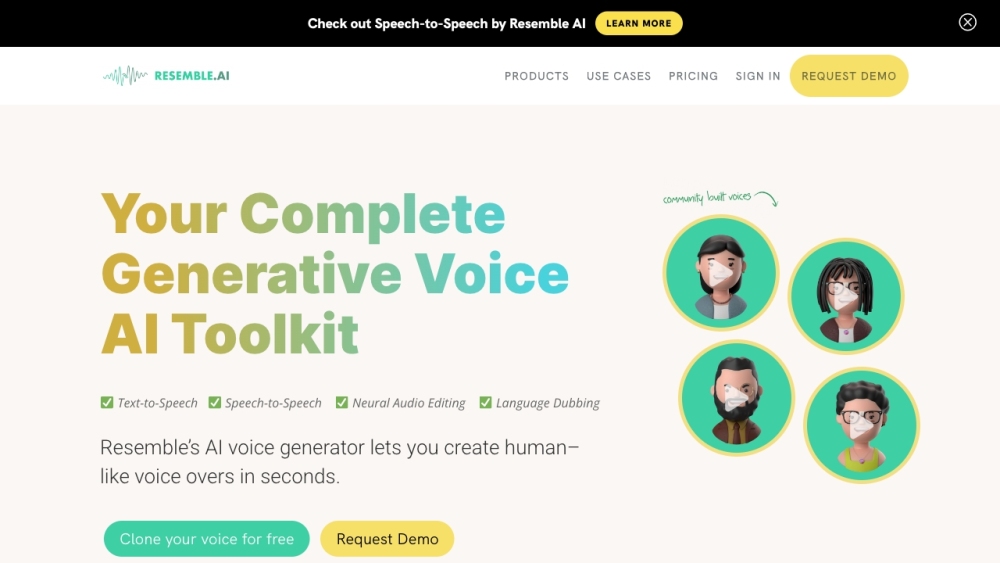
Crea voces sintéticas realistas en solo segundos. Experimenta el poder de la tecnología de vanguardia que ofrece soluciones de audio realistas adaptadas a tus necesidades.
Find AI tools in YBX
Related Articles
Refresh Articles