Apple lance OpenELM : des modèles d'IA open source compacts optimisés pour des performances sur appareils.
Most people like

Textbuddy.com est un puissant outil conçu pour aider les écrivains à améliorer la clarté et la concision de leur écriture. En analysant le texte en anglais simple et accessible, Textbuddy.com optimise le processus d'écriture et garantit que votre message résonne efficacement auprès des lecteurs.
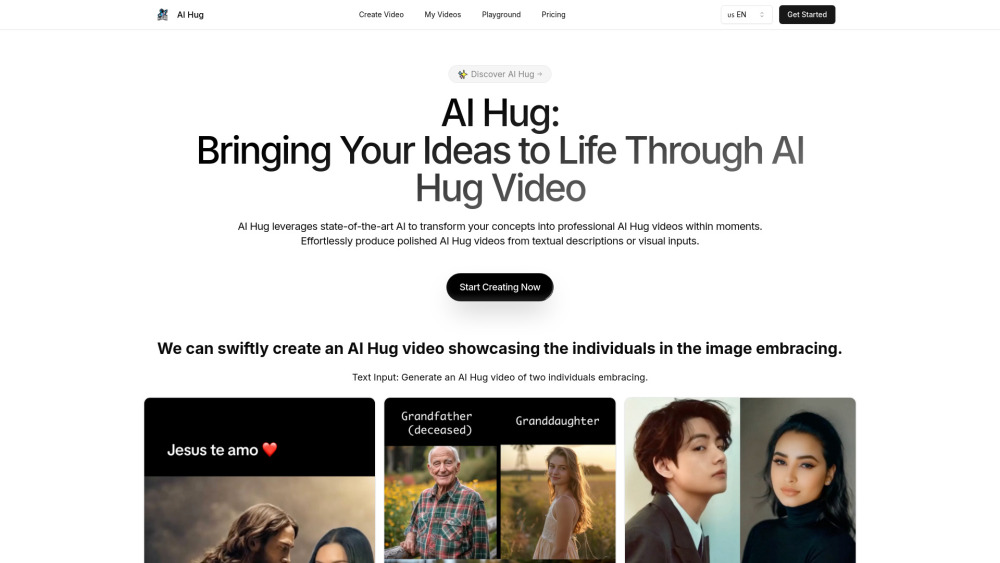
Transformez des textes et des images en vidéos professionnelles époustouflantes sans effort grâce à notre outil d'IA. Élevez votre création de contenu avec une technologie de pointe qui simplifie le processus de réalisation vidéo, le rendant accessible à tous. Que vous soyez un marketeur, un éducateur ou un créateur de contenu, cet outil d'IA innovant est conçu pour donner vie à vos idées avec aisance et précision. Découvrez dès aujourd'hui le futur de la production vidéo !

Découvrez la plateforme de gestion de finances tout-en-un conçue pour stimuler votre croissance et votre succès financier.
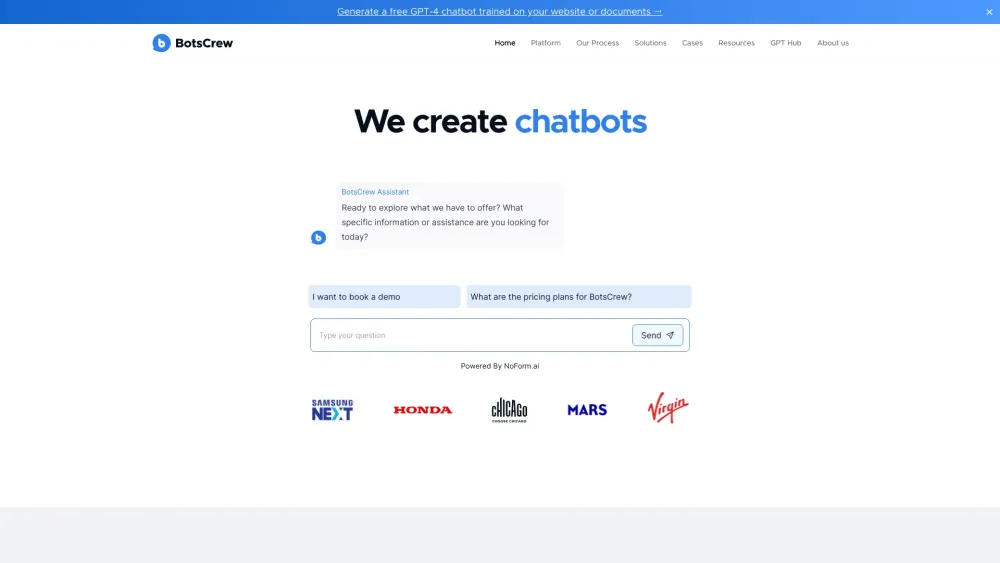
Dans le paysage numérique d'aujourd'hui, les entreprises se tournent de plus en plus vers des chatbots personnalisés intelligents pour améliorer les interactions avec les clients et optimiser leurs opérations. En tirant parti de la technologie avancée de l'IA, ces chatbots peuvent offrir un support personnalisé, répondre aux questions en temps réel et améliorer considérablement l'expérience utilisateur. Que vous cherchiez à augmenter vos ventes, à améliorer le service client ou à automatiser des tâches répétitives, investir dans le développement de chatbots sur mesure est un choix stratégique pour toute organisation visionnaire. Découvrez le potentiel transformateur des chatbots et comment ils peuvent stimuler la croissance et l'engagement de votre marque.
Find AI tools in YBX
Related Articles
Refresh Articles