Classement : GPT-4 d'OpenAI Atteint le Taux le Plus Bas d'Hallucinations
Most people like

Caktus AI est une plateforme innovante conçue spécialement pour les étudiants, offrant des outils d'IA puissants pour l'écriture, la résolution de problèmes, le codage et diverses tâches académiques. Développez votre potentiel avec les fonctionnalités de Caktus AI, adaptées pour améliorer l'apprentissage et augmenter la productivité.
Améliorer les paiements commerciaux globaux sécurisés est essentiel dans l'économie interconnectée d'aujourd'hui. Alors que les entreprises s'appuient de plus en plus sur des transactions internationales, garantir la sécurité et la fiabilité des processus de paiement est plus crucial que jamais. Avec les bonnes mesures en place, les entreprises peuvent minimiser les risques, rationaliser leurs opérations et favoriser la confiance dans le commerce transfrontalier. Prioriser des solutions de paiement sécurisées protège non seulement vos intérêts financiers, mais ouvre également la voie à une croissance durable sur le marché mondial.
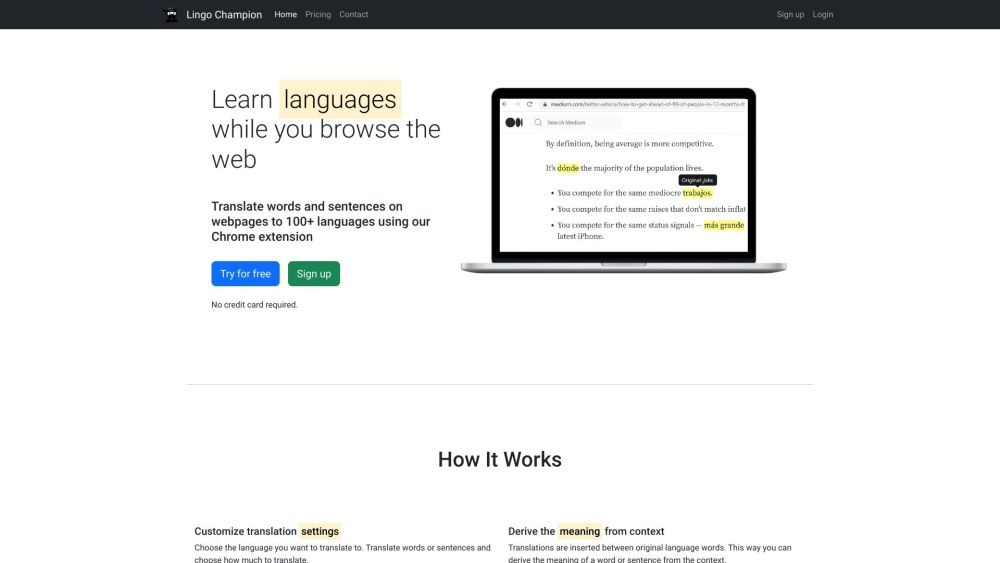
Découvrez le plaisir d'apprendre des langues sans effort en naviguant sur le web avec Lingo Champion ! Améliorez vos compétences en temps réel sans interrompre votre expérience en ligne.
Améliorez la réussite des clients, optimisez les processus et augmentez la productivité grâce à des outils sur mesure et des flux de travail optimisés. Découvrez comment des solutions personnalisables peuvent transformer vos opérations commerciales dès aujourd'hui.
Find AI tools in YBX
Related Articles
Refresh Articles