Des Anciens de Google DeepMind Lance Bioptimus : Pionniers du Développement du Premier Modèle d’IA Universel pour la Biologie
Most people like
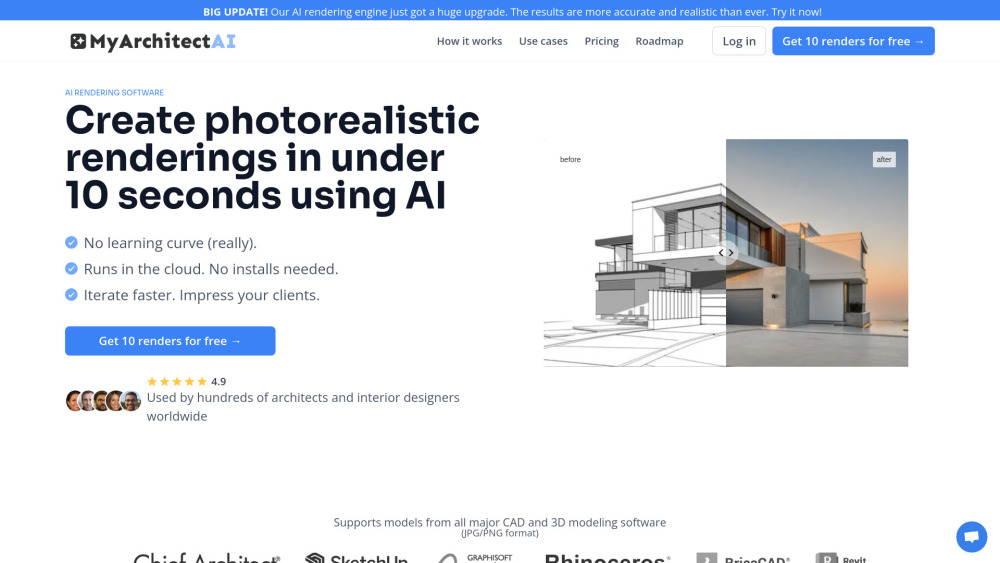
Découvrez un logiciel de rendu IA à la pointe de la technologie, capable de réaliser des visuels architecturaux photoréalistes époustouflants en un instant. Vivez la puissance transformative de l'intelligence artificielle pour améliorer vos présentations architecturales et optimiser votre flux de travail de design. Que vous soyez architecte, designer ou promoteur, nos outils avancés vous permettront de créer des environnements immersifs qui captiveront clients et parties prenantes. Débloquez dès aujourd'hui l'avenir du rendu architectural !

Présentation de notre application de coaching personnel innovante alimentée par l'IA, conçue pour améliorer votre expérience de fitness à domicile ou à la salle de sport. Cet outil à la pointe de la technologie personnalise les entraînements en fonction de vos objectifs individuels, garantissant que vous tiriez le meilleur parti de chaque séance d'exercice. Que vous soyez débutant ou athlète confirmé, notre application s'adapte à vos besoins, offrant des routines sur mesure qui maximisent les résultats et vous motivent à rester sur la bonne voie. Préparez-vous à une aventure fitness transformative à portée de main !
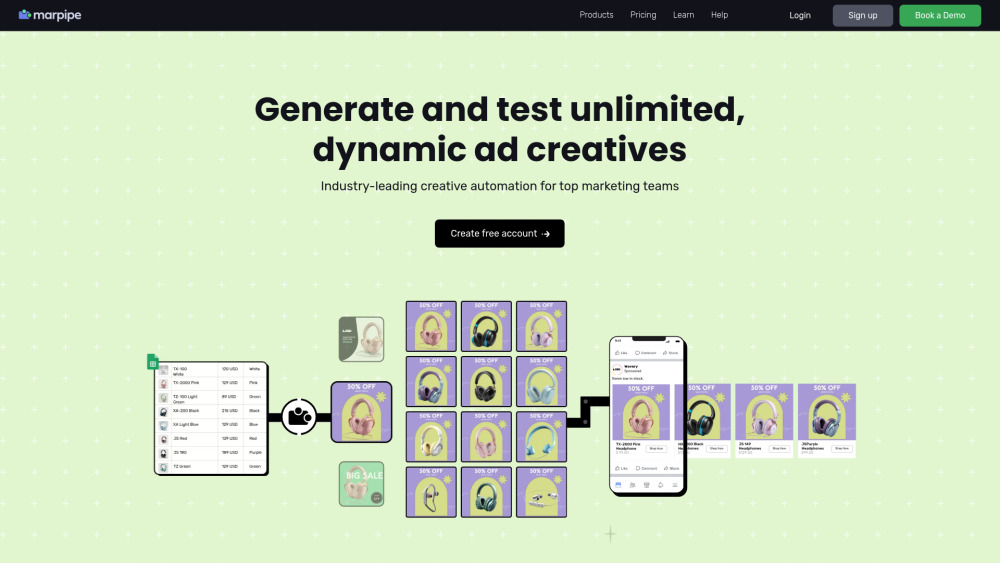
Présentation d'une plateforme automatisée conçue pour la création et le test des Annonces Produits Dynamiques. Simplifiez vos efforts publicitaires et améliorez l'engagement grâce à des solutions sur mesure qui optimisent votre stratégie marketing de manière efficace.
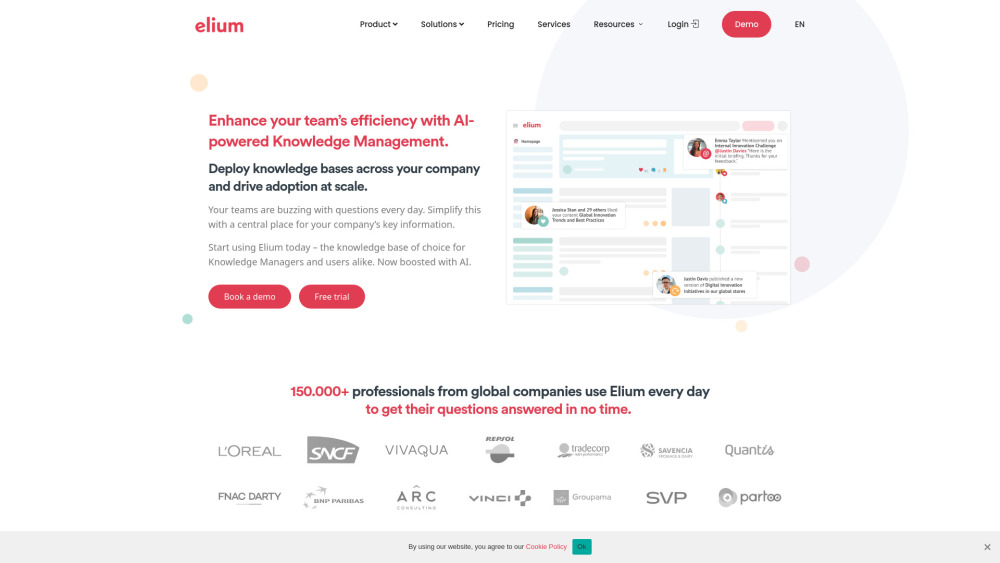
Dans le paysage numérique d'aujourd'hui, en constante évolution, une plateforme de partage de connaissances joue un rôle essentiel dans l'exploitation de l'intelligence collective. En offrant un espace centralisé où individus et organisations peuvent échanger idées et ressources, ces plateformes favorisent la collaboration et l'innovation. Cela permet non seulement aux utilisateurs d'accéder à des perspectives variées, mais également de prendre des décisions éclairées et de résoudre efficacement des problèmes. Rejoignez-nous pour découvrir comment une plateforme de partage de connaissances performante peut renforcer l'intelligence collective et transformer notre façon d'apprendre et de travailler ensemble.
Find AI tools in YBX
Related Articles
Refresh Articles