Google dévoile Lumiere : un modèle de diffusion espace-temps pour créer des vidéos IA réalistes.
Most people like

Pollinations.AI est une plateforme en ligne innovante qui utilise des algorithmes d'IA avancés pour créer des œuvres d'art époustouflantes et uniques. Grâce à son interface conviviale, elle permet à chacun d'explorer le monde fascinant de l'art généré par l'IA.
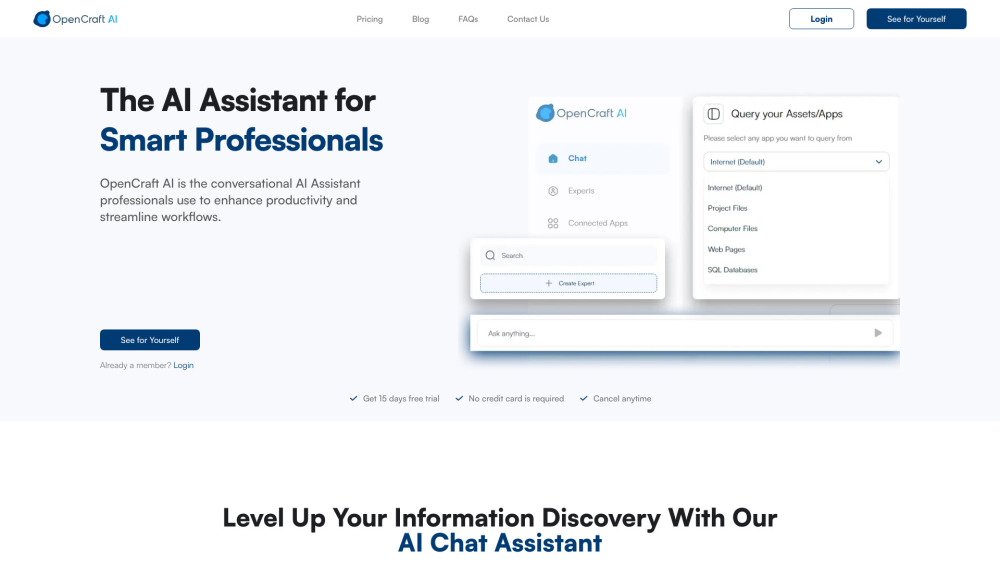
Débloquez la puissance d'un assistant IA conçu spécialement pour les professionnels désireux d'améliorer leur productivité et d'optimiser leurs flux de travail. Cet outil innovant simplifie les tâches, vous permettant de vous concentrer sur ce qui compte vraiment dans votre travail. Découvrez un nouveau niveau d'efficacité avec un assistant spécialisé à portée de main.
Débloquez votre potentiel avec une préparation et un retour d'expérience d'entretien alimentés par l'IA
Êtes-vous prêt à réussir votre prochain entretien d'embauche ? Notre plateforme alimentée par l'IA propose une préparation personnalisée et des retours d'expérience perspicaces pour renforcer votre confiance et améliorer votre performance. En utilisant des technologies de pointe, nous vous aidons à peaufiner vos réponses et à développer des compétences clés pour vous démarquer sur un marché du travail compétitif. Que vous soyez un jeune diplômé ou un professionnel aguerri, nos outils vous préparent à réussir dans n'importe quelle situation d'entretien. Augmentez vos chances d'obtenir le poste de vos rêves dès aujourd'hui !
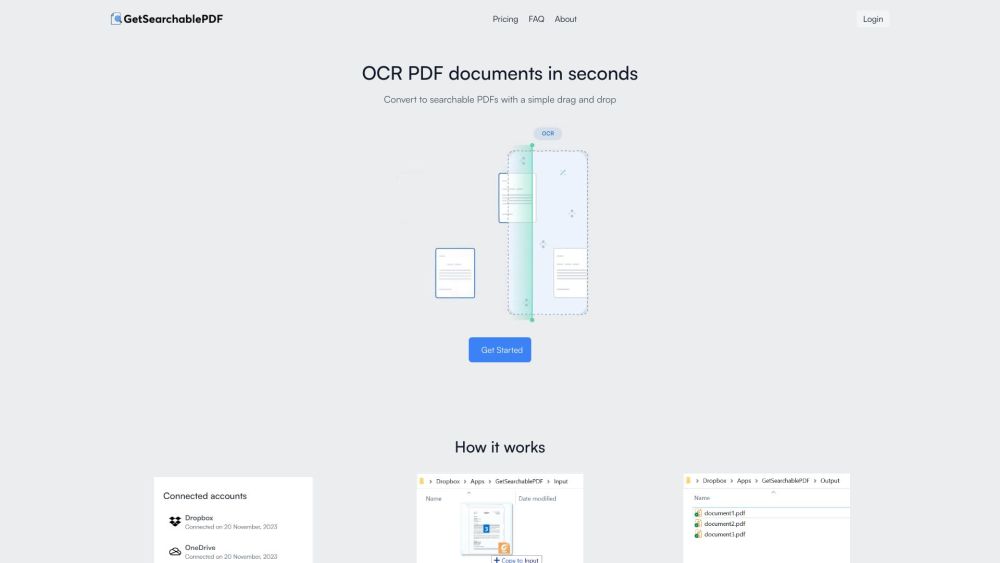
Transformez vos documents PDF grâce à notre solution avancée d'OCR en masse, offrant une grande précision même pour les images et le texte manuscrit. Améliorez votre flux de travail en convertissant sans effort de grands volumes de PDF tout en préservant les détails importants et la clarté.
Find AI tools in YBX
Related Articles
Refresh Articles