NVIDIA dévoile son nouveau modèle d'IA 8B : haute précision et efficacité, compatible avec les stations de travail RTX.
Most people like

Élevez votre expérience ChatGPT avec des demandes soigneusement conçues. Déverrouillez le plein potentiel de l'intelligence artificielle en utilisant des suggestions réfléchies qui stimulent la créativité et l'engagement.
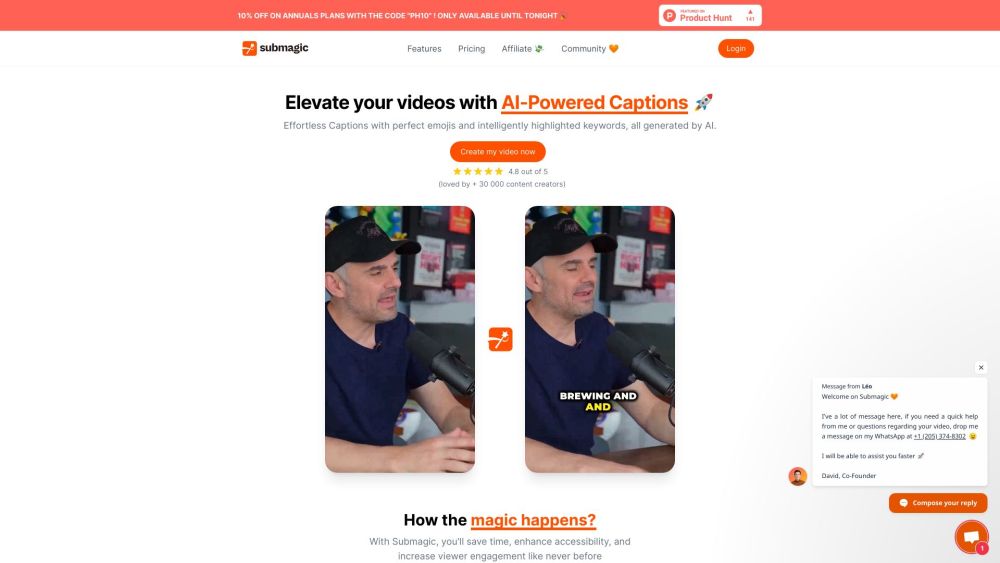
Créez des légendes captivantes remplies d'émojis pour votre contenu court. Engagez votre audience et faites briller vos publications !
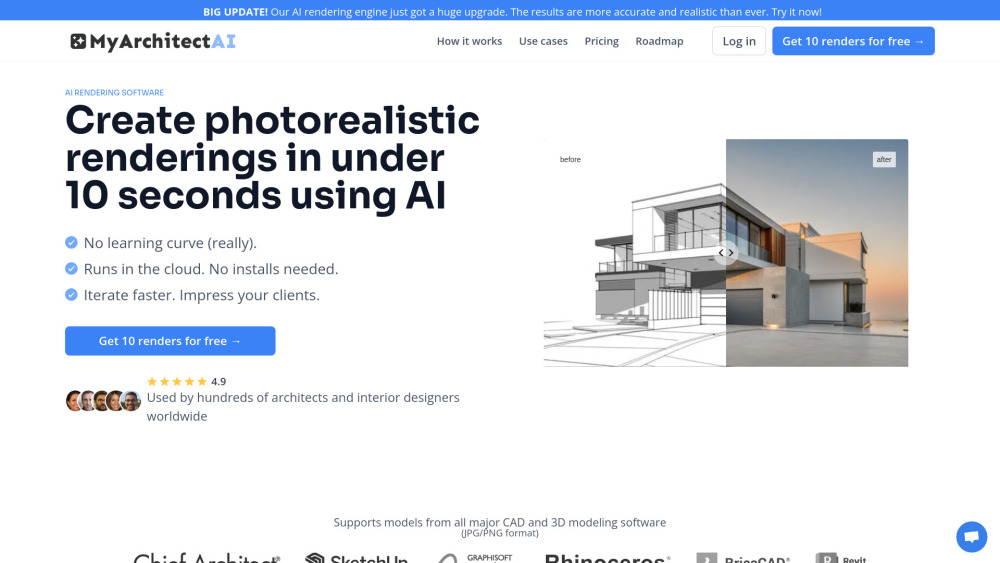
Découvrez un logiciel de rendu IA à la pointe de la technologie, capable de réaliser des visuels architecturaux photoréalistes époustouflants en un instant. Vivez la puissance transformative de l'intelligence artificielle pour améliorer vos présentations architecturales et optimiser votre flux de travail de design. Que vous soyez architecte, designer ou promoteur, nos outils avancés vous permettront de créer des environnements immersifs qui captiveront clients et parties prenantes. Débloquez dès aujourd'hui l'avenir du rendu architectural !
Find AI tools in YBX
Related Articles
Refresh Articles