RecurrentGemma de Google intègre une IA linguistique avancée pour améliorer les performances des appareils de périphérie.
Most people like
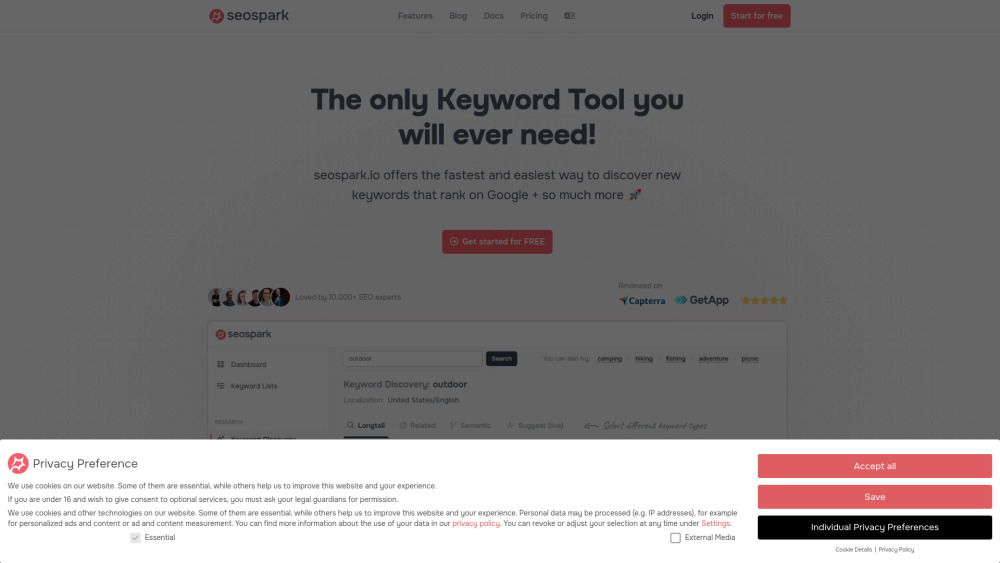
Débloquez tout le potentiel de votre présence en ligne avec notre puissant outil SEO conçu pour la recherche de mots-clés et le développement d'une stratégie de contenu efficace. Que vous soyez un marketeur numérique chevronné ou un novice, notre plateforme intuitive vous fournit les informations nécessaires pour identifier des mots-clés à fort impact et créer un contenu captivant qui résonne avec votre audience. Élevez votre jeu SEO et générez du trafic organique en tirant parti de stratégies basées sur des données adaptées à votre niche. Commencez dès aujourd'hui à optimiser pour une meilleure visibilité et des classements de recherche améliorés !
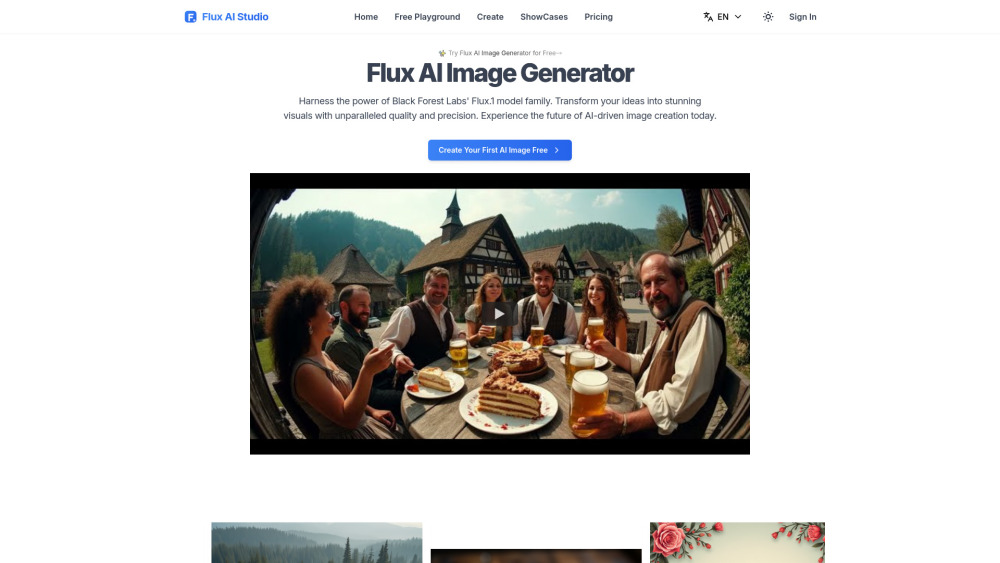
Découvrez notre plateforme alimentée par l'intelligence artificielle qui transforme votre texte en images magnifiques. Grâce à une technologie avancée, vous pouvez donner vie à vos mots en toute simplicité, créant des visuels à la mesure de votre imagination. Rejoignez les nombreux utilisateurs qui ont libéré le potentiel de transformer des idées en graphismes captivants grâce à nos outils innovants.
Découvrez la puissance de l'externalisation éthique du marquage de données pour les modèles d'IA. Dans le paysage concurrentiel actuel, un marquage de données précis et éthique est essentiel pour le développement de solutions d'intelligence artificielle avancées. Les entreprises se tournent de plus en plus vers l'externalisation pour des services de marquage efficaces et fiables qui respectent les normes éthiques. Cette introduction offre un aperçu des avantages de cette externalisation et de son impact sur la performance des modèles d'IA et leur conformité.

Découvrez l'éditeur vidéo AI ultime pour créer des clips engageants sur les réseaux sociaux
Libérez la puissance de notre éditeur vidéo AI avancé, conçu pour vous aider à créer sans effort des vidéos époustouflantes pour les réseaux sociaux. Que vous soyez un créateur chevronné ou que vous débutiez, cet outil intuitif simplifie le processus de montage, vous permettant de produire un contenu captivant qui séduit votre audience et renforce votre présence en ligne.
Find AI tools in YBX
