人間のヒントを活用した強化学習:AIシステムの誤り修正に向けた革新的アプローチ
Most people like
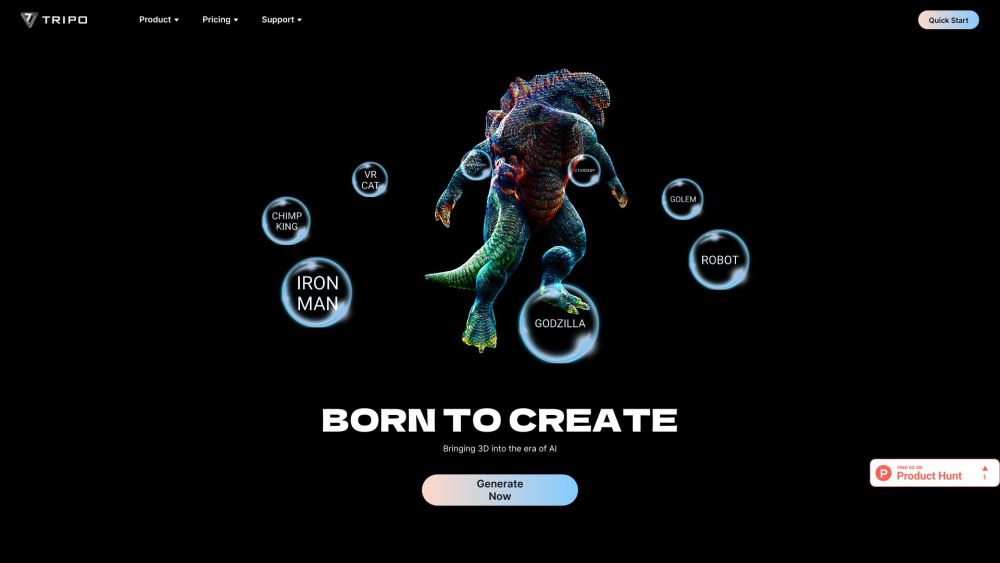
瞬時に単一の画像を驚くべき3Dアセットに変換!この革新的なプロセスにより、平面的なビジュアルをダイナミックな三次元モデルにシームレスに変換し、クリエイティブなプロジェクトを向上させることができます。アーティスト、ゲーム開発者、コンテンツクリエイターの方々にとって、この技術はワークフローを強化し、アイデアを迅速かつ正確に具現化します。
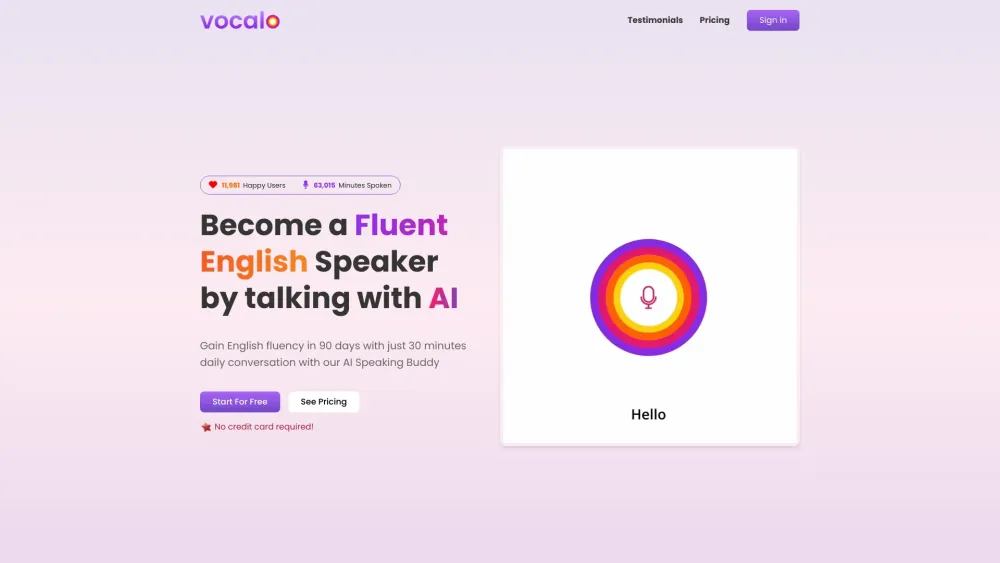
私たちのAI駆動の言語練習プラットフォームで言語スキルを向上させましょう。この革新的なツールは、あなたの独自のニーズに合わせたパーソナライズされた学習体験を提供し、短期間で流暢さと自信を身につける手助けをします。
すべてのコンテンツ制作ニーズに応えるAIプラットフォームを紹介します!マーケター、ブログ運営者、ビジネスオーナーの方々に最適なこの革新的なソリューションは、コンテンツ生成を効率化し、質を確保します。当社のAI駆動ツールが、クリエイティビティと生産性を向上させ、ターゲットオーディエンスに合わせた魅力的で影響力のあるコンテンツをこれまで以上に簡単に制作できるようにします。コンテンツ制作の未来を今すぐ取り入れましょう!
Find AI tools in YBX
Related Articles
Refresh Articles