Adobeの研究者、AIの新たなブレイクスルーで2D画像からわずか5秒で3Dモデルを生成
Most people like
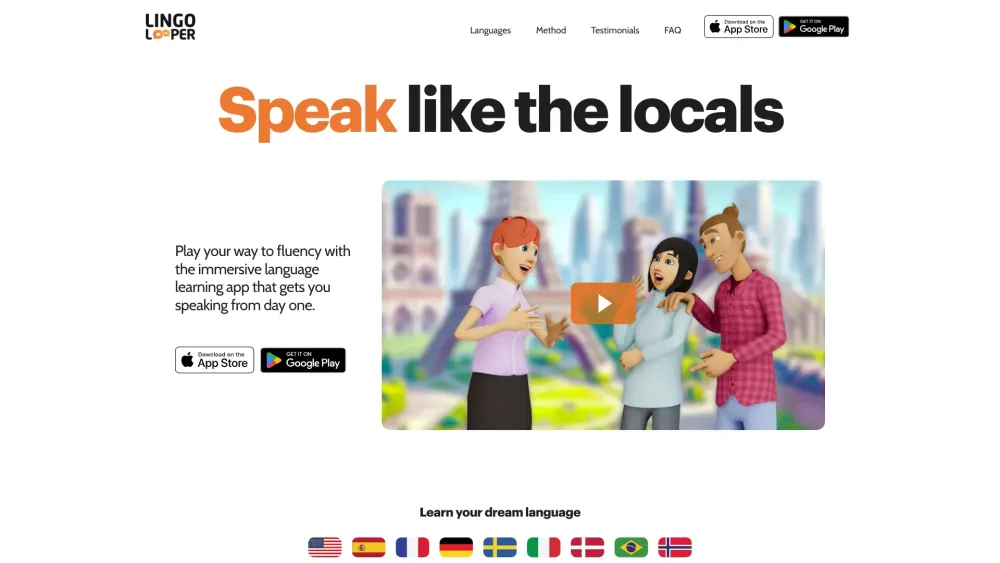
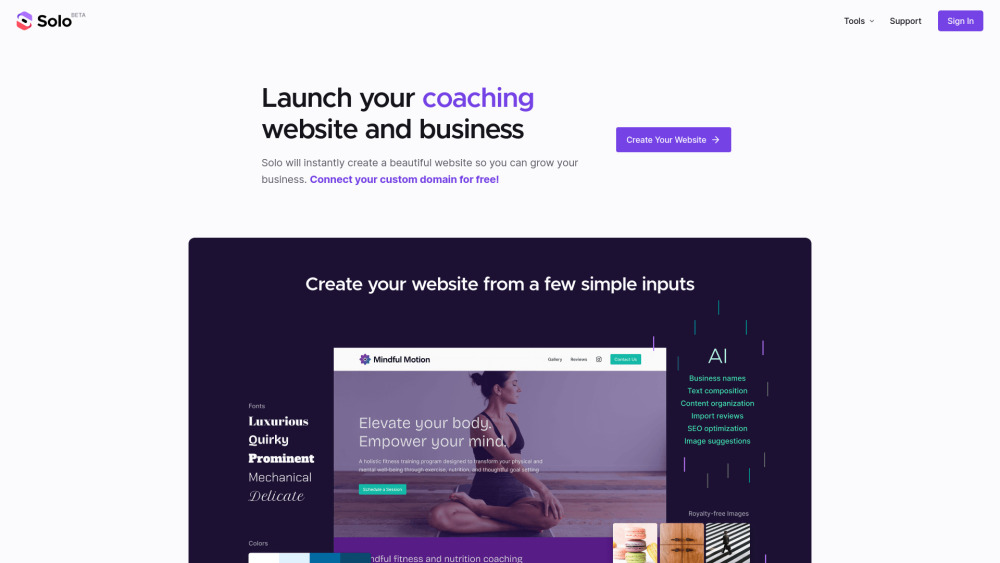
今日のデジタル環境では、あらゆる規模のビジネスにとってインパクトのあるオンラインプレゼンスが不可欠です。AIウェブサイトクリエイターは、プロフェッショナルなウェブサイトを構築するプロセスを簡素化し、起業家や企業が手軽に魅力的なサイトを作成できるようにします。先進技術を活用することで、これらのツールはカスタマイズ可能なテンプレートと使いやすいインターフェースを提供し、ユーザーがブランドアイデンティティを確立し、顧客とのエンゲージメントを向上させることを可能にします。AIウェブサイトクリエイターがどのようにビジネス戦略を変革し、オンラインでの成功を促進できるかを発見しましょう。

あなたの想像力を解き放とう!当社のユニークなキャラクター名生成ツールを使えば、ファンタジー小説の作成、ロールプレイングゲームの開発、物語のための記憶に残るキャラクター作りに役立ちます。この革新的なツールは、独自で適切な名前を生成できるよう設計されています。あなたのクリエイティブなニーズに合わせた多様なオプションを探索し、すべてのキャラクターがその個性と物語を反映した名前で際立つようにしましょう。完璧な名前を見つける旅を今すぐ始めましょう!
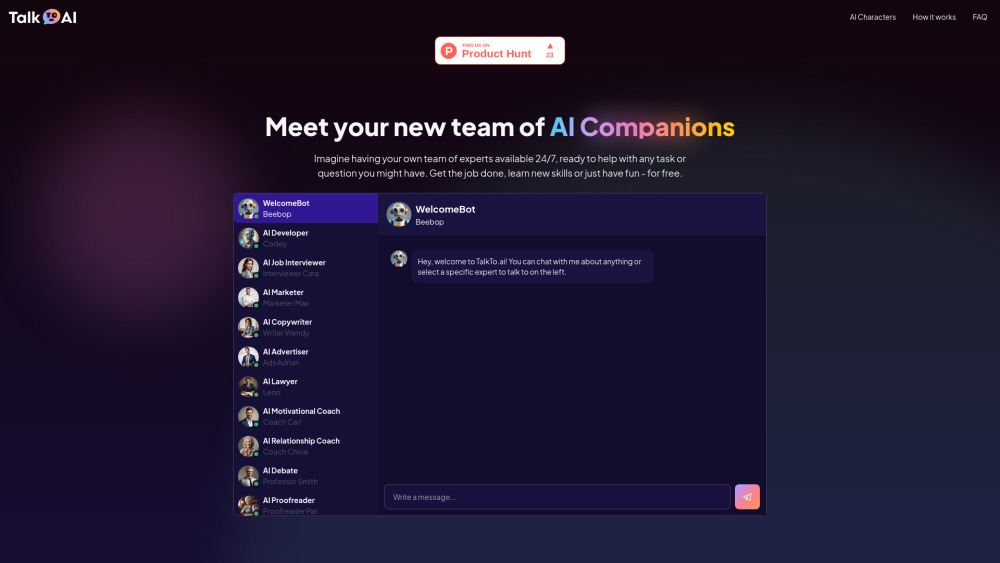
多様なAI仲間との活気ある会話を楽しもう—完全に無料です!それぞれのAIが持つ独自の個性や洞察を発見し、チャット体験を楽しく、充実させましょう。今日からAIとの交流の可能性を引き出してみませんか!
Find AI tools in YBX
Related Articles
Refresh Articles