AppleのToolSandboxが浮き彫りにした問題:オープンソースAIは独自モデルに遅れを取る
Most people like
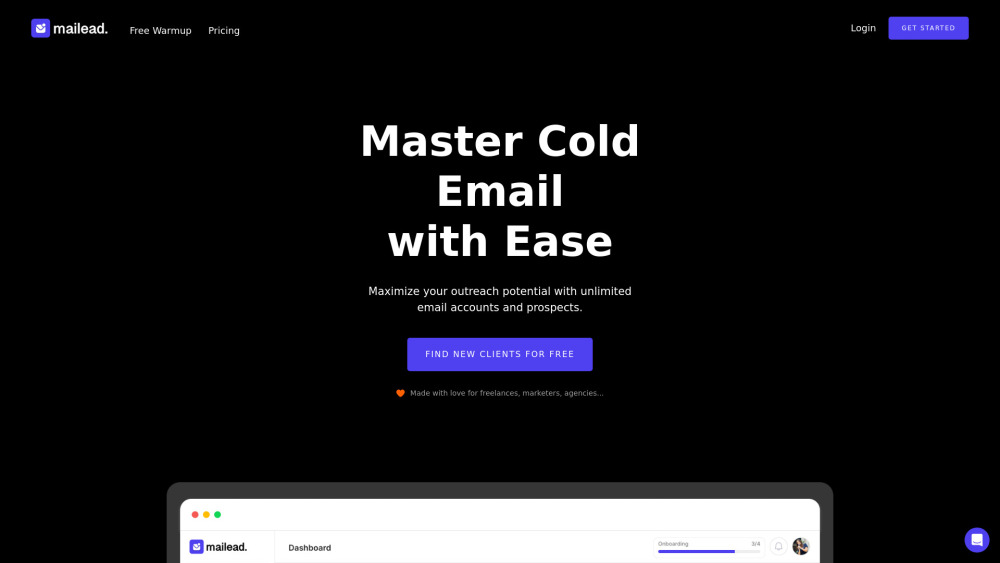
手間いらずでアウトリーチ活動を自動化する究極のコールドメールツールを発見しましょう。無限のアカウントを簡単に管理でき、メールキャンペーンを効率化してエンゲージメントを向上させましょう!
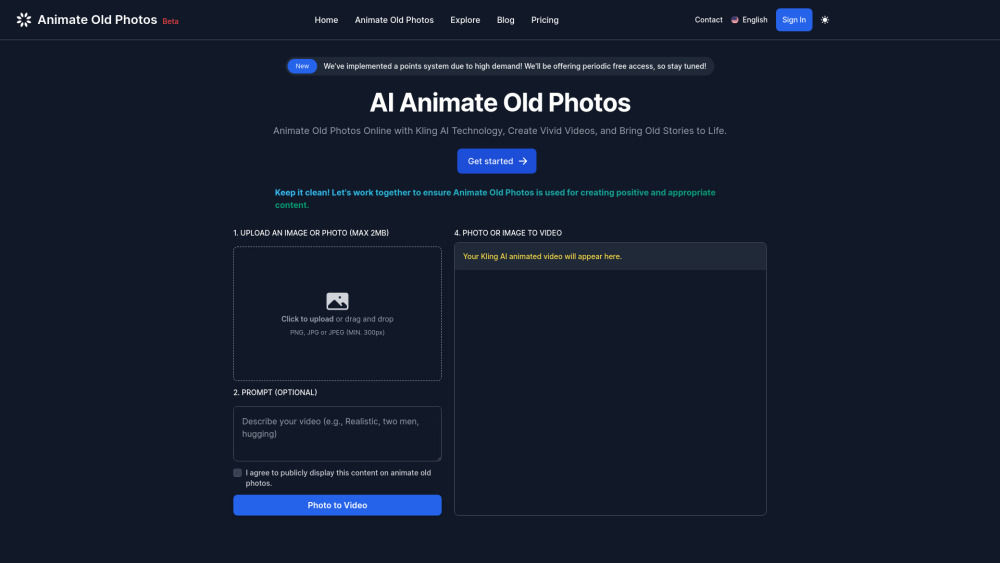
AIツールを使った古い写真の魅力的な動画への変換
デジタル時代において、大切な思い出に新たな命を吹き込むことがこれほど簡単になったことはありません。古い写真をダイナミックな動画にアニメーションするAIツールを使えば、過去の瞬間を魅力的な形で甦らせることができます。先進的な技術を活用することで、静止画を強化し、動きや音で命を吹き込みます。歴史的な写真をシェア可能な動画の宝物に変えて、注目を集め、懐かしさを呼び起こす方法を見つけましょう。

革新的なAIツールを紹介します。このツールは、重要な学習資料を要約し、カスタマイズされたクイズを作成することで、学習セッションを効率化します。この強力なツールは、学生が学習の効率、記憶力、試験準備を向上させる手助けをし、学業成功を目指すすべての人にとってかけがえのない資源となります。
Find AI tools in YBX
Related Articles
Refresh Articles