GAIAベンチマーク:次世代AIが現実世界の課題に挑む
Most people like
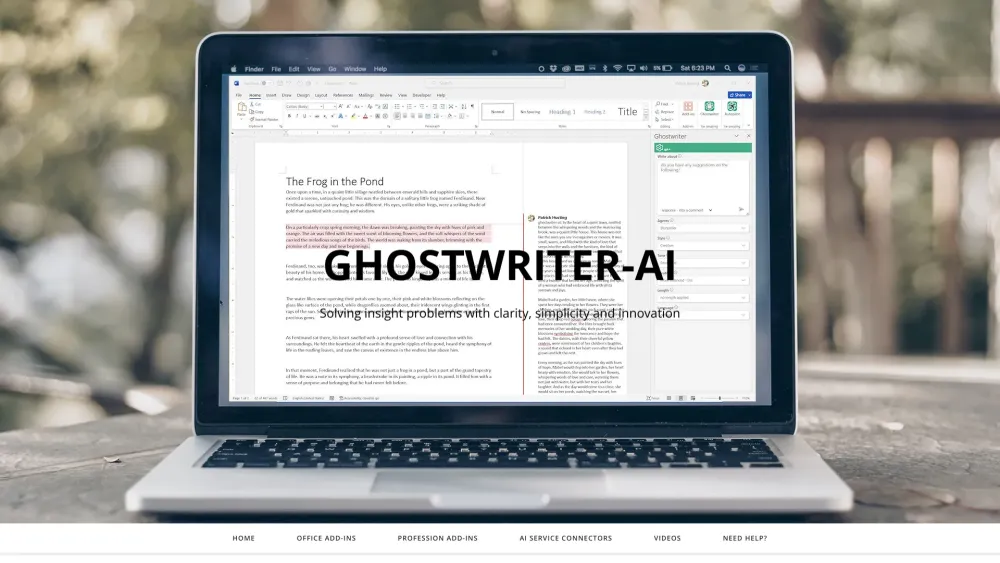
Microsoft Office体験を革新的なAIソリューションで変革する
生産性を向上させ、ワークフローを効率化するために設計された画期的なAI革新で、Microsoft Officeの真の潜在能力を引き出しましょう。これらの先進的なツールが、あなたの好きなOfficeアプリケーション内で作成、コラボレーション、コミュニケーションする方法をどのように変革できるかを発見してください。退屈な作業の自動化や文書作成の向上を求めている場合でも、私たちのAIソリューションは、あなたのMicrosoft Office体験を再定義します。
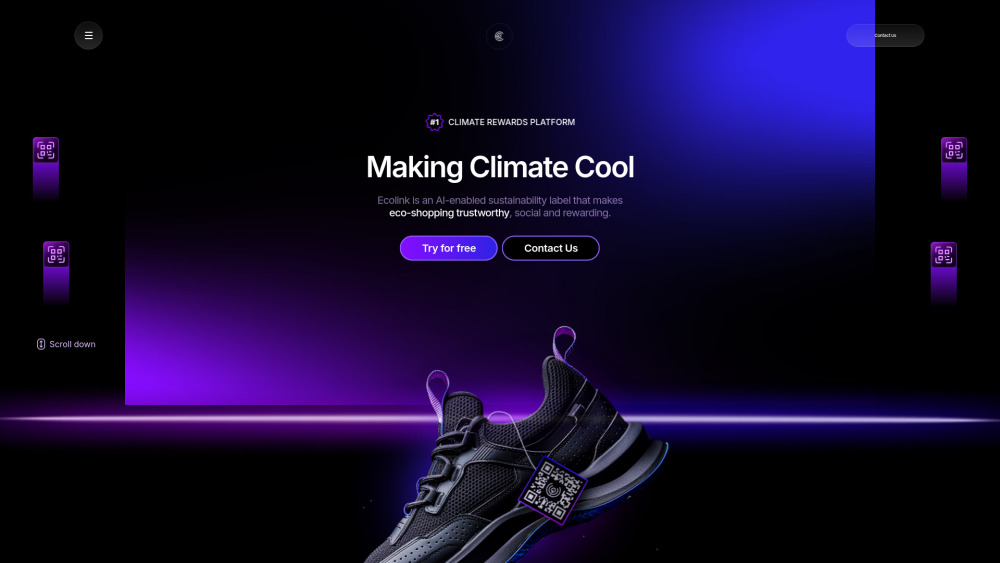
環境保全へのアプローチを革新する、AIとブロックチェーンを活用した持続可能性プラットフォームを紹介します。人工知能とブロックチェーン技術の力を借りて、このプラットフォームは透明性の向上、効率の増加、さまざまな産業における持続可能なプラクティスの促進を目指します。最先端の技術を通じて、持続可能性の未来を共に変革しましょう。
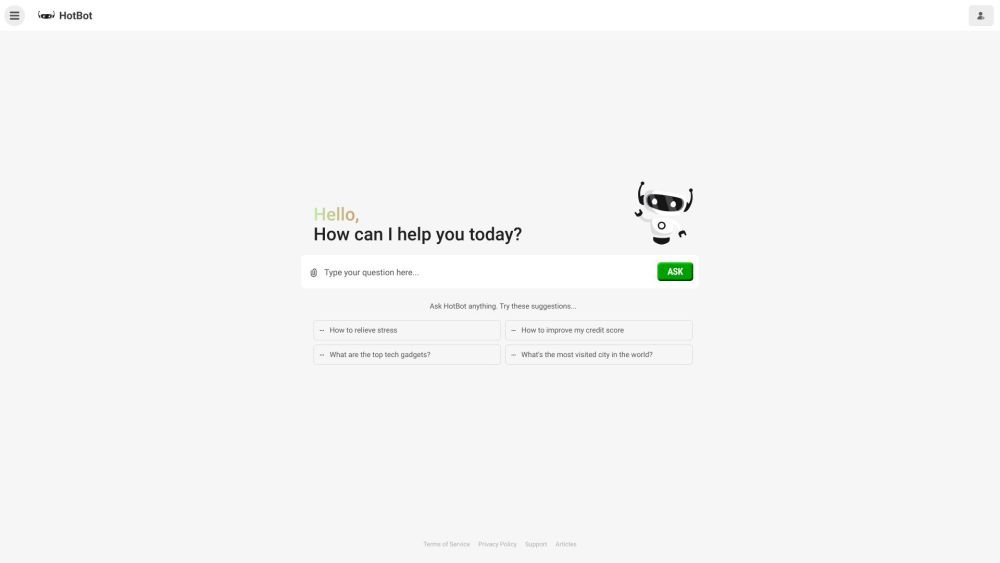
AI駆動の検索エンジンで、情報検索の未来を体験してください。知的で正確な回答を即座に提供し、大量のデータを手軽にナビゲートできます。詳細な情報から迅速な事実まで、当社の高度なアルゴリズムが常に賢い答えを提供します。
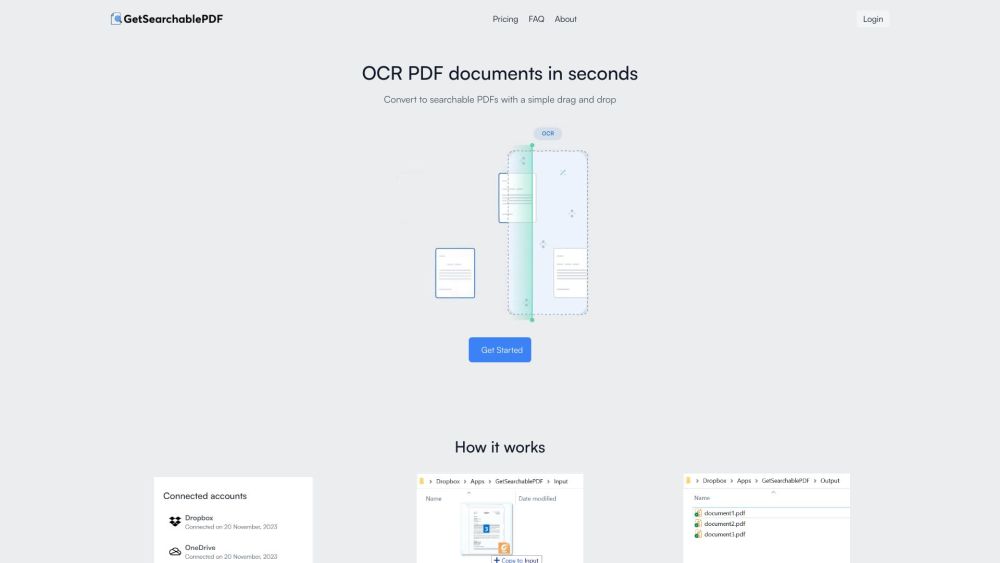
高度なバルクOCRソリューションでPDF文書を変革し、画像や手書きのテキストでも高い精度を実現します。重要な詳細や明瞭さを保ちながら、大量のPDFを簡単に変換してワークフローを向上させましょう。
Find AI tools in YBX
