NVIDIAのAIチームがYouTubeとNetflixの動画を無断でスクレイピングした疑惑
Most people like
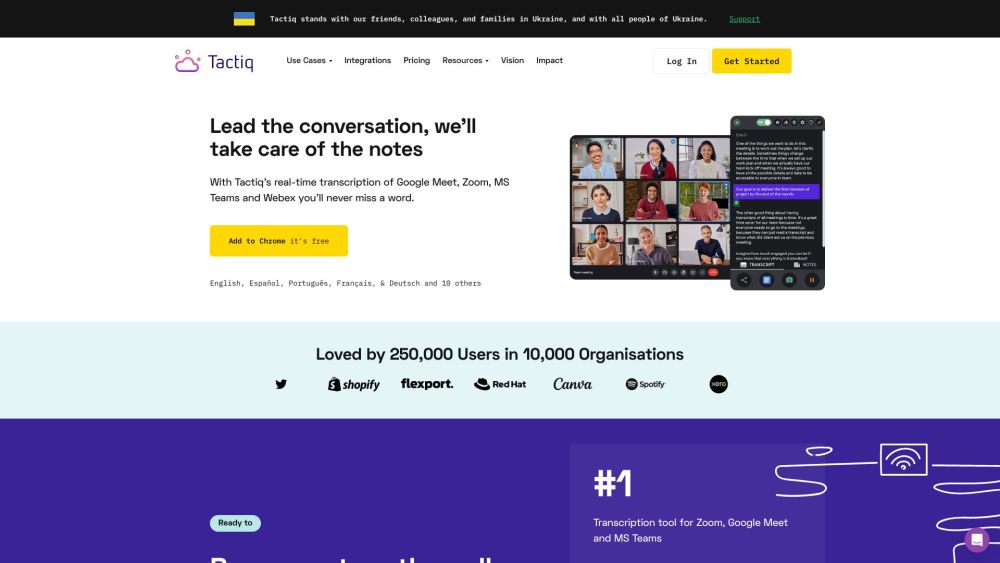
Tactiqは、オンラインミーティング専用に設計された優れたトランスクリプションツールで、リアルタイムのスムーズな文字起こしと簡潔な会議の要約を提供します。Tactiqを活用して生産性を向上させ、バーチャルなディスカッションを効果的にキャッチし整理するための最適なソリューションとして、コラボレーションを強化しましょう。

Typli.AIは、デジタルマーケターやコンテンツクリエイター向けに特化した革新的なAI駆動のプラットフォームです。コンテンツ生成を簡素化し、最適化を強化することで、ユーザーが手間なく高品質な素材を作成できるようにします。
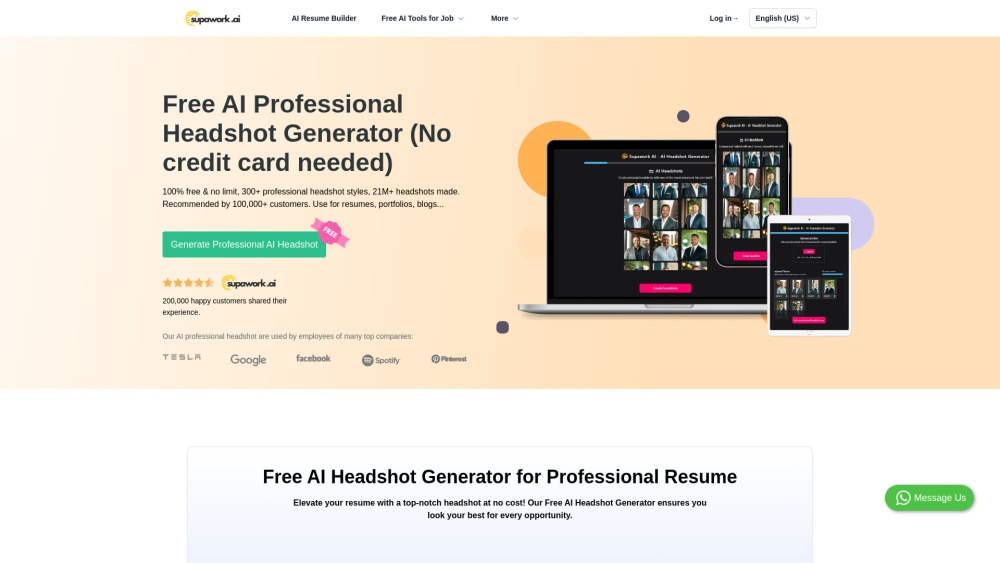
300以上のプロフェッショナルなヘッドショットスタイルと100以上のカスタマイズ可能な背景を探索し、2100万枚以上のポートレートが作成され、5万以上の満足した顧客に信頼されています。AI生成のビジネスヘッドショット、ポートレート、アバター、プロフィール画像を発見し、履歴書、ポートフォリオ、ブログに最適な一枚で、あなたのパーソナルブランドを今日変革しましょう!
Find AI tools in YBX
Related Articles
Refresh Articles