RedditがGoogleと6000万ドルの提携を締結し、AIツールを強化—最新報告
Most people like
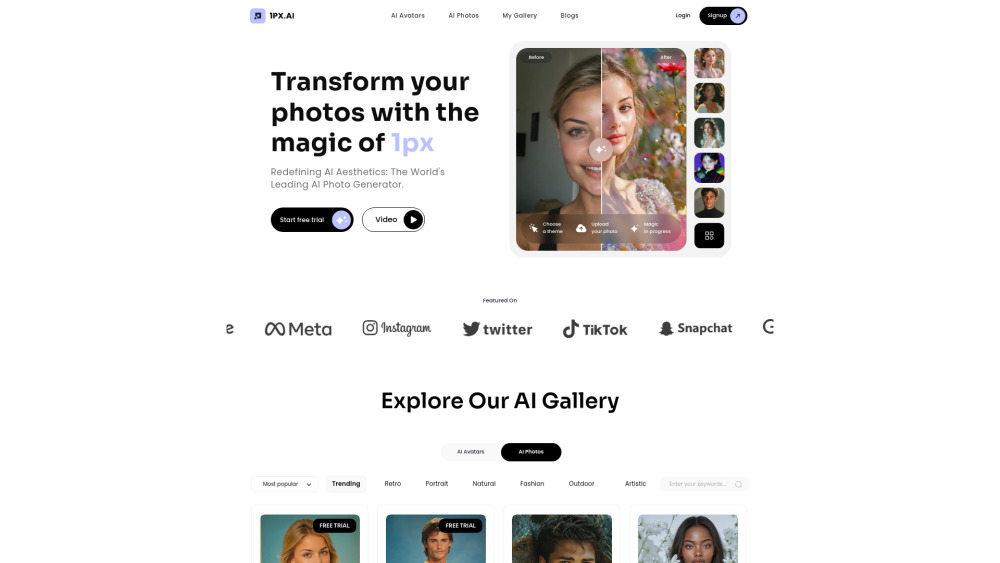
最先端のAI写真およびアバター生成プラットフォームを紹介します。ここでは革新と創造性が融合しています!最先端の技術を駆使し、ユーザーは驚くようなパーソナライズされた画像やアバターを簡単に作成できます。オンラインプレゼンスを強化したり、ユニークなソーシャルメディアグラフィックをデザインしたり、単に創造力を探求したりするために、私たちのプラットフォームはあなたのアイデアを数分で高品質なビジュアルに変えます。可能性の世界に飛び込み、あなたのスタイルに合わせた魅力的な写真やアバターを生成するのがいかに簡単かを体験してください!
AIを活用したコピーライティングの力を駆使して、あなたのeコマースビジネスを向上させましょう。知能的な自動化が、魅力的な商品説明や心を掴むマーケティングコンテンツ、パーソナライズされた顧客メッセージをどのように生み出せるかを探求してください。すべてはエンゲージメントを高め、売上を増加させるために設計されています。今日、あなたのオンラインストアにおけるAIの変革的な影響を発見しましょう!
Find AI tools in YBX
Related Articles
Refresh Articles