新たなオープンソースAIビジョンモデルがChatGPTに挑む:考慮すべき重要課題
Most people like
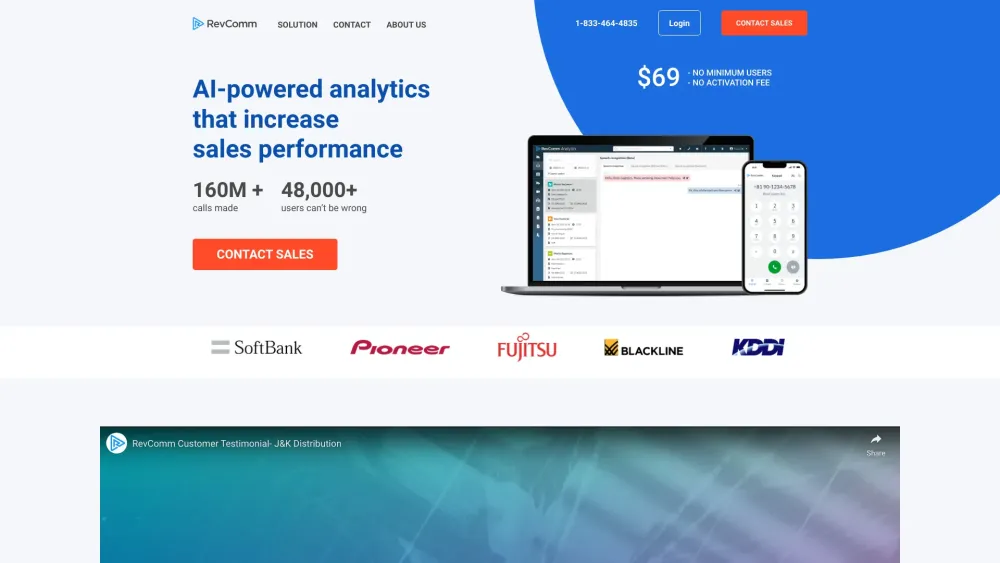
先進的な会話分析機能を搭載したAI駆動のIP電話で、コミュニケーションを革新しましょう。最先端の技術を活用して、ビジネスの対話を実用的なインサイトに変換し、業務の効率を向上させます。
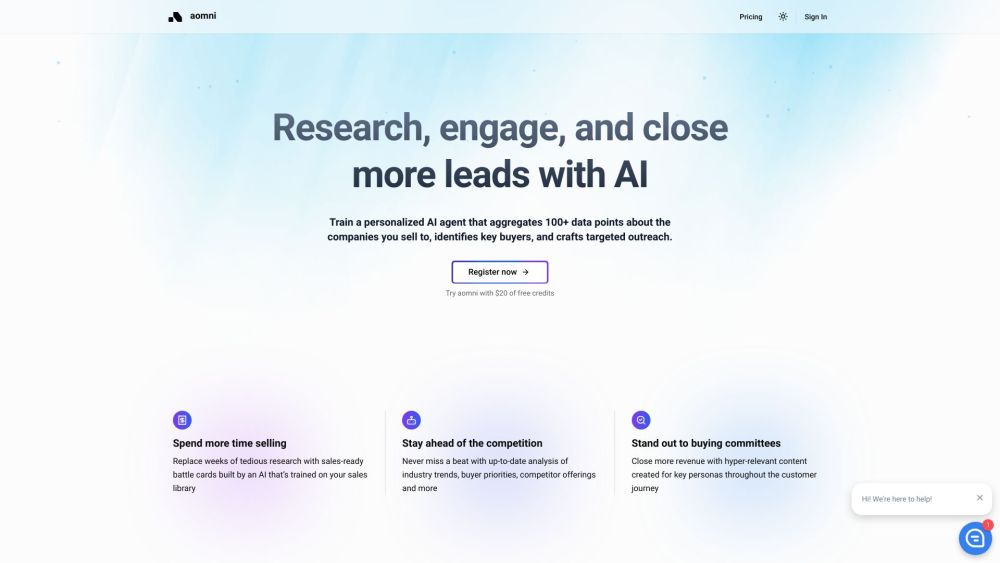
AI搭載のツールキットで販売力を引き出しましょう。販売プロセスを合理化し、効率を高め、パフォーマンスを向上させる最先端技術を体験してください。経験豊富なプロフェッショナルでも、初心者でも、このツールキットは効果的に契約を締結し、収益成長を促進するための賢いソリューションを提供します。今日、私たちの高度なAI機能で販売の未来を探求しましょう。
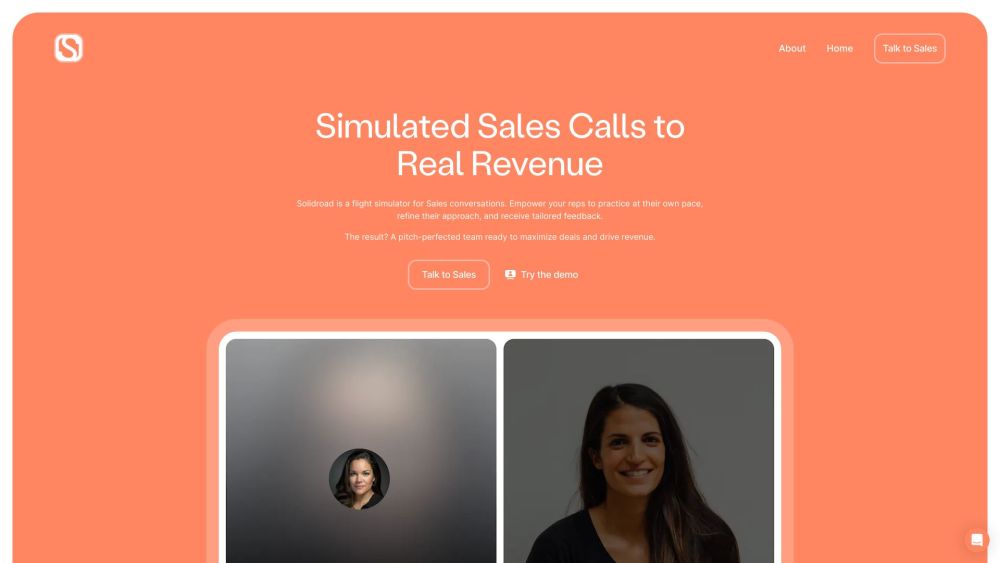
営業コール専用に設計されたAI会話シミュレーターで、販売戦略を向上させましょう。この革新的なツールは、営業の専門家がスキルを練習し、磨くことを可能にし、すべてのやり取りが魅力的かつ説得力のあるものになります。営業へのアプローチを変革し、最先端のAI技術を活用した効果的なコミュニケーションの影響を実感してください。
Find AI tools in YBX
Related Articles
Refresh Articles