MIT와 Cohere가 협력하여 감사된 AI 데이터셋을 추적하고 필터링하는 플랫폼을 출시했습니다.
Most people like

오늘날의 경쟁적인 환경에서 기업들은 지속적으로 제품 개선을 위한 혁신적인 솔루션을 모색하고 있습니다. AI 모델 통합 도구의 등장— 인공지능을 제품 개발 프로세스에 매끄럽게 통합하도록 설계된 첨단 플랫폼입니다. 이 도구는 AI 기능을 활용하여 제품의 기능을 향상시키고 성능을 최적화하며 사용자 참여를 촉진하여 귀사의 브랜드를 최전선에 위치시킵니다. AI 통합이 어떻게 귀사의 제품 제공을 혁신하고 고객 만족도를 높일 수 있는지 알아보십시오.
궁극적인 AI 기반 솔루션으로 Google Ads 캠페인을 제작하고 개선해보세요. 이 강력한 도구는 광고 생성 및 최적화를 혁신하여 비즈니스가 온라인 광고의 영향을 극대화할 수 있도록 지원합니다.
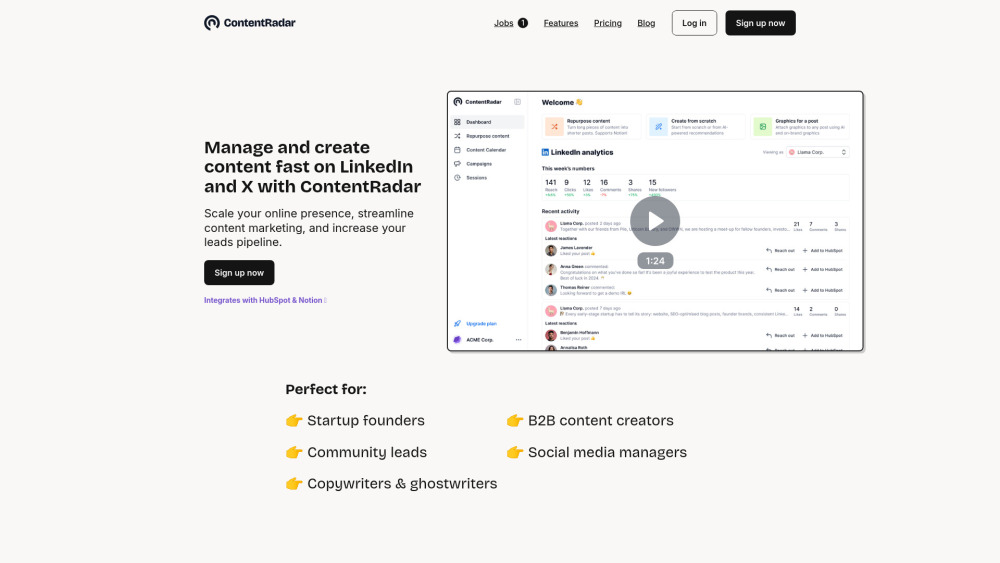
링크드인과 X를 위해 특별히 설계된 AI 기반 콘텐츠 관리 작업공간으로 소셜 미디어 전략을 한 단계 끌어올리세요. 게시물 작성 과정을 간소화하고, 청중 참여를 강화하며, 콘텐츠 기획 프로세스를 효율화하세요. 인공지능의 힘으로 온라인 존재감을 변화시키고 네트워킹 잠재력을 극대화하세요!
Find AI tools in YBX
Related Articles
Refresh Articles