인간 큐 제공 강화 학습: AI 시스템의 오류를 수정하는 혁신적인 접근법
Most people like
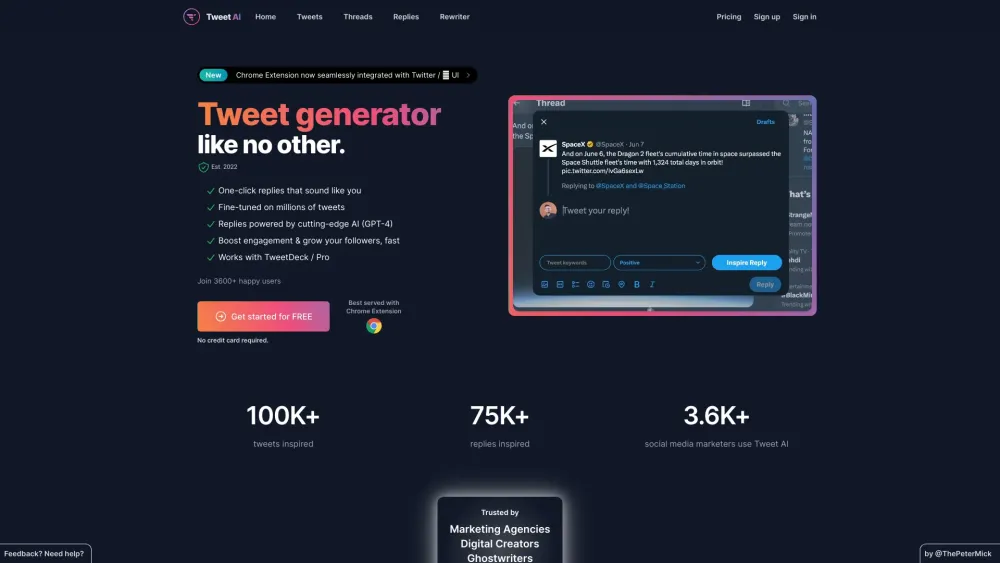
X에서 판매 및 참여 증대
오늘날의 경쟁 시장에서 X에서 판매를 늘리고 청중 참여를 높이는 것은 그 어느 때보다 중요합니다. 이 플랫폼은 목표 청중과 연결하고 전환을 촉진하며 지속적인 관계를 구축할 수 있는 독특한 기회를 제공합니다. X에서의 존재감을 극대화하기 위한 효과적인 전략을 구현함으로써 귀사의 브랜드 가시성을 높이고 놀라운 결과를 달성할 수 있습니다. 접근 방식을 변화시킬 준비가 되셨나요? X에서 판매 및 참여를 최적화하는 방법을 살펴보겠습니다!
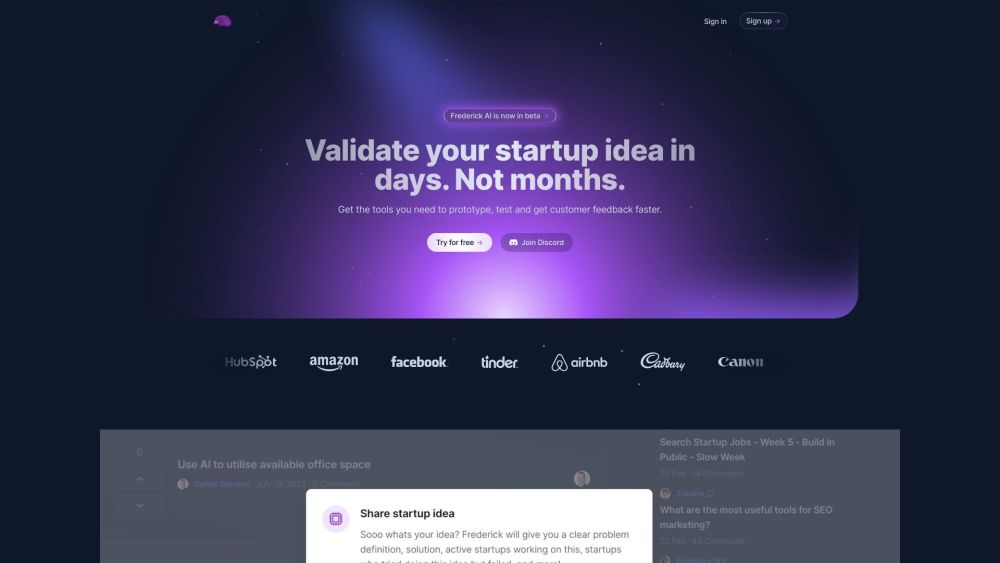
스타트업 아이디어 검증 및 AI 기반 비즈니스 플랜 작성
오늘날의 경쟁적인 환경에서 스타트업 아이디어가 공감을 얻는 것은 성공을 위한 핵심입니다. 혁신적인 AI 도구를 활용하면 개념을 효율적으로 검증하고 돋보이는 종합 비즈니스 플랜을 작성할 수 있습니다.
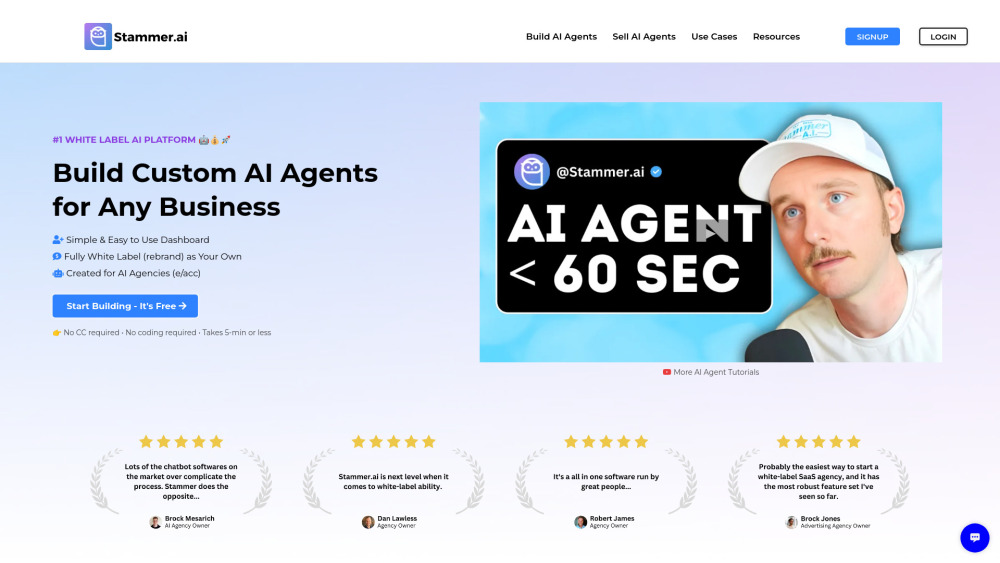
화이트 라벨 AI SaaS 솔루션의 힘을 발견하세요. 지능형 AI 에이전트를 만들고 재판매하기 위해 설계되었습니다. 고유한 요구를 충족하도록 맞춤화된 플랫폼으로 비즈니스 제공을 혁신하고 고객 경험을 향상시키세요. 우리의 혁신적인 기술이 어떻게 귀하의 브랜드를 높이고 수익 성장에 기여할 수 있는지 탐구해 보세요.
Find AI tools in YBX
Related Articles
Refresh Articles