Acesso Limitado a LLMs? Snowflake Lança Inferência Entre Regiões para Maior Disponibilidade
Most people like
Em uma era em que a tecnologia revoluciona indústrias, as soluções de IA estão remodelando significativamente os setores bancário e de FinTech. Desde a melhoria do atendimento ao cliente até a otimização da gestão de riscos, a integração da inteligência artificial está se mostrando essencial para as instituições financeiras que buscam inovação e eficiência. Descubra como os processos impulsionados por IA não apenas otimizam operações, mas também oferecem experiências personalizadas para os clientes, preparando o terreno para uma nova era nas finanças.
Beautiful.ai é uma ferramenta inovadora projetada para capacitar equipes a criar apresentações visualmente impressionantes de forma fácil. Com recursos intuitivos, simplifica o processo de design, tornando-o acessível a qualquer usuário.
Revolucione suas Aprovações de Crédito com Nossa Solução Financeira Impulsionada por IA
Desbloqueie o futuro das aprovações de crédito com nossa inovadora solução financeira movida por IA. Projetada para agilizar o processo de aprovação, esta ferramenta inovadora melhora eficiência, precisão e velocidade, garantindo que você tome decisões de crédito informadas rapidamente. Experimente o poder transformador da inteligência artificial nas finanças, abrindo caminho para avaliações de crédito mais rápidas e confiáveis.
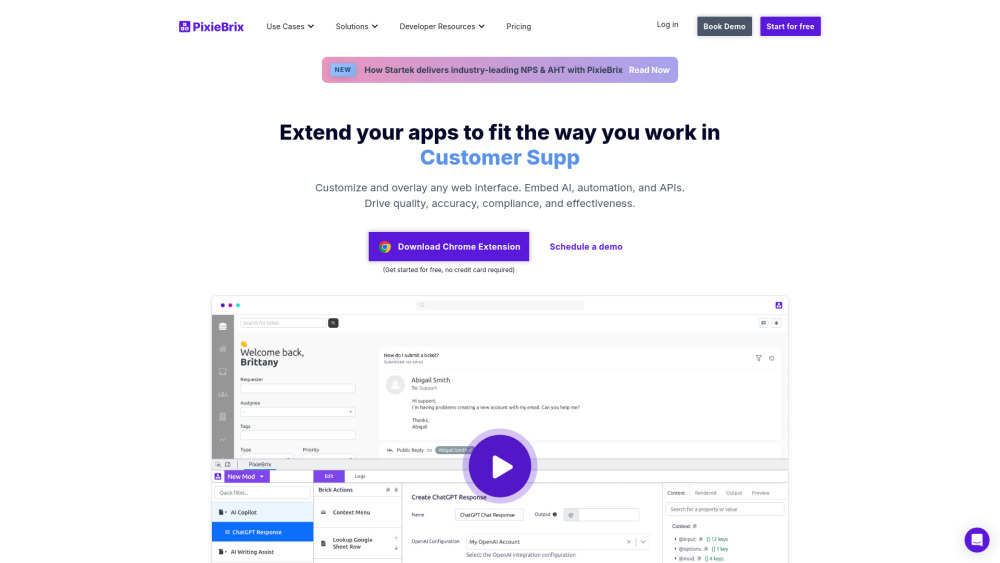
Descubra a plataforma low-code definitiva, projetada para criar modificações personalizadas no navegador e automatizar tarefas com facilidade. Adote uma abordagem simplificada que permite aos usuários melhorar sua experiência de navegação sem a necessidade de extensos conhecimentos em programação. Se você deseja otimizar fluxos de trabalho ou personalizar suas interações na web, esta plataforma oferece a solução perfeita.
Find AI tools in YBX
Related Articles
Refresh Articles