Apple, NVIDIA e Anthropic Acusadas de Uso Não Autorizado de Transcrições do YouTube para Treinamento de Modelos de IA
Most people like
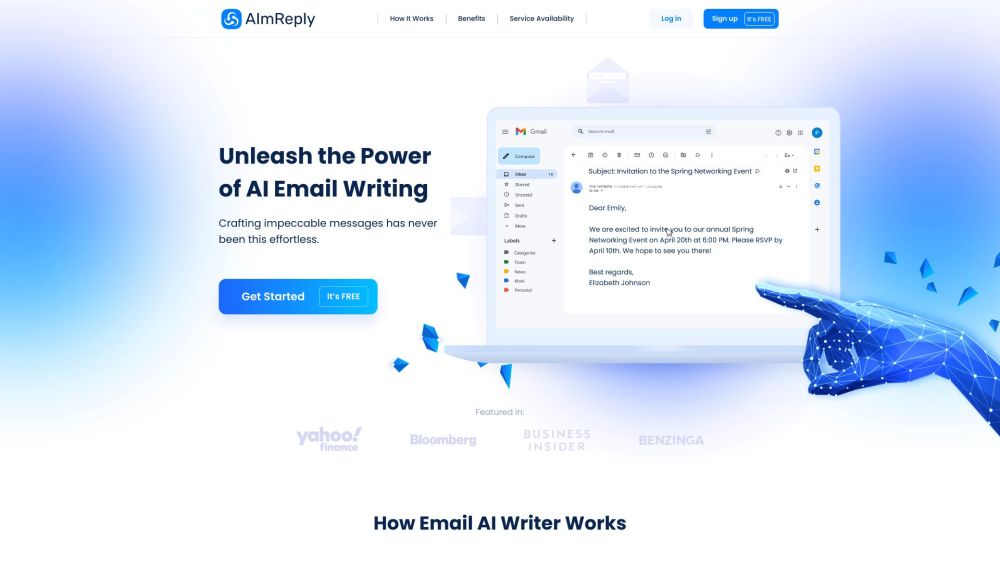
Aumente Sua Produtividade com Nosso Assistente de E-mail com IA
Desbloqueie todo o potencial da sua caixa de entrada com nosso avançado Assistente de E-mail com IA, projetado para simplificar sua comunicação e aumentar sua produtividade. Transforme a maneira como você gerencia e-mails, responda de forma eficiente e priorize suas tarefas sem esforço. Experimente uma abordagem mais inteligente para e-mails hoje mesmo!
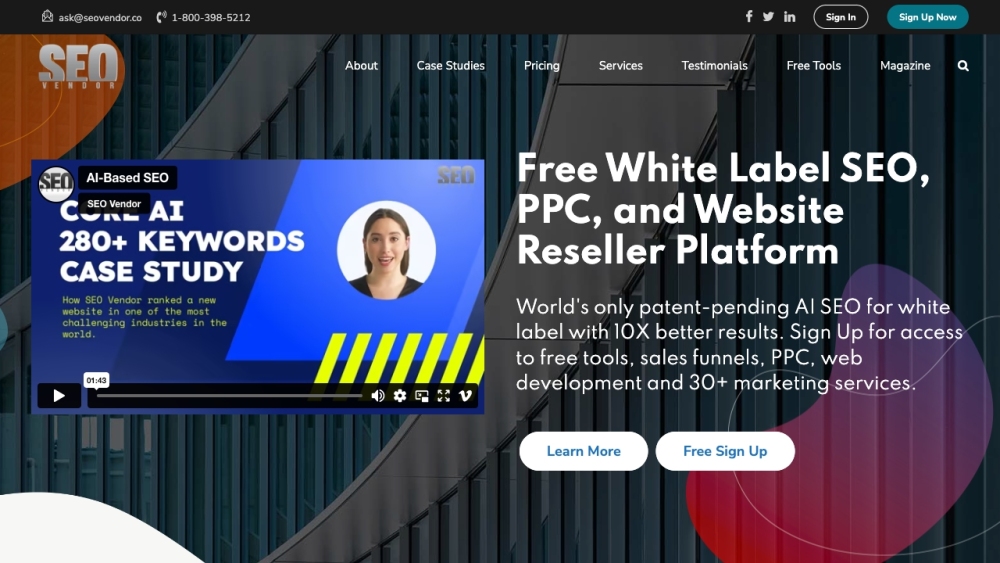
As agências têm a oportunidade de rebrandear e revender serviços de SEO, PPC e design de sites em seu próprio nome, permitindo que ampliem suas ofertas de serviços e elevem sua presença no mercado.
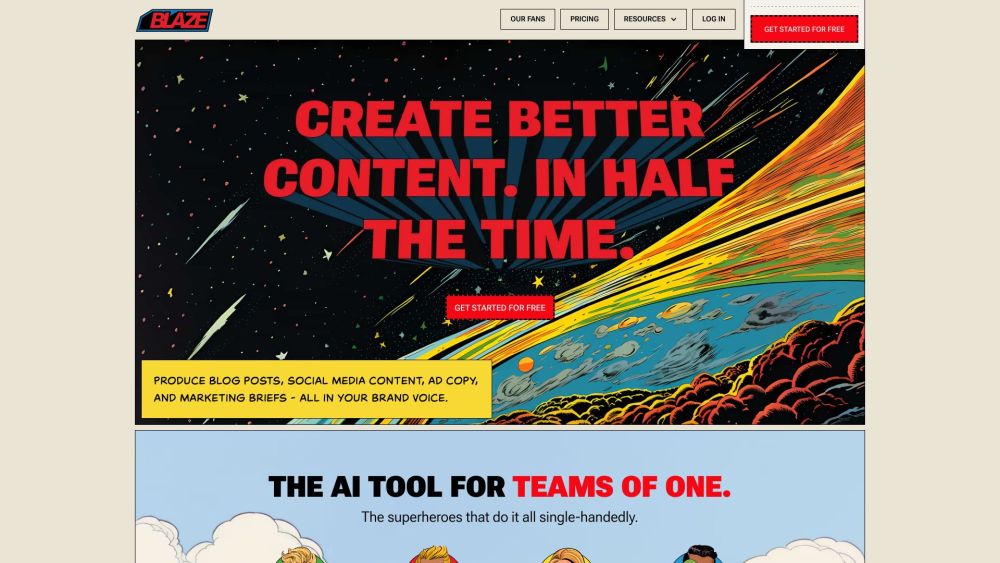
Apresentamos uma ferramenta impulsionada por IA, projetada para criar conteúdos que capturam perfeitamente a voz da sua marca. Se você deseja engajar seu público ou aprimorar sua identidade de marca, esta solução inovadora transforma suas ideias em narrativas cativantes que ressoam com seu mercado-alvo. Eleve sua estratégia de conteúdo hoje mesmo com tecnologia de ponta adaptada especificamente para suas necessidades.
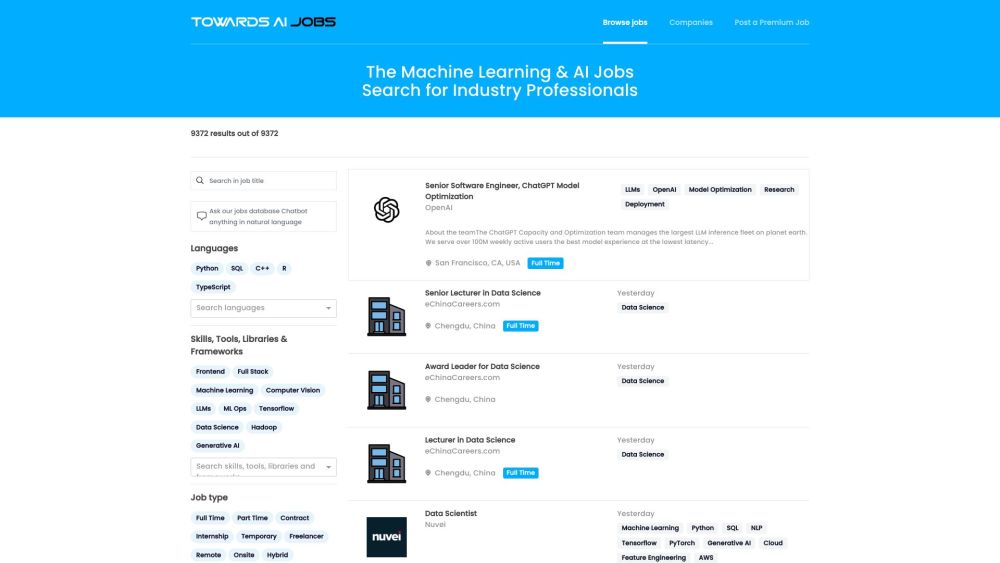
Descubra a plataforma de busca de emprego definitiva, projetada exclusivamente para profissionais de aprendizado de máquina. Conecte-se com as principais empresas e explore oportunidades de trabalho personalizadas no campo em constante evolução do aprendizado de máquina. Comece hoje mesmo sua jornada em direção ao emprego dos seus sonhos!
Find AI tools in YBX
Related Articles
Refresh Articles