Classificação: O GPT-4 da OpenAI Alcança a Menor Taxa de Alucinações
Most people like
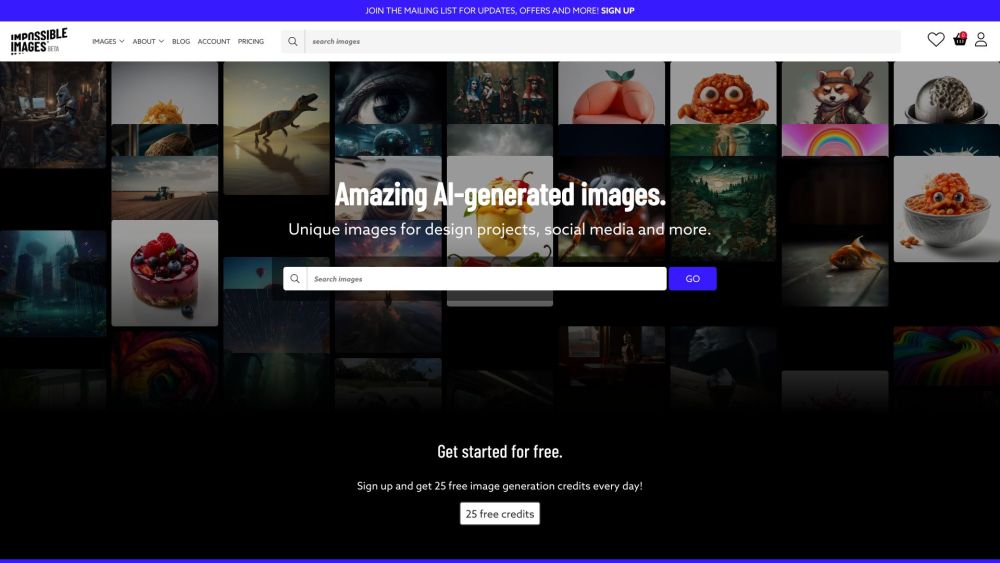
Descubra uma biblioteca de imagens de estoque impulsionada por IA, que oferece uma vasta coleção de imagens isentas de royalties, downloads simples e atualizações regulares para manter seus projetos atuais e envolventes. Aprimore seu trabalho criativo com nosso inovador gerador de imagens!
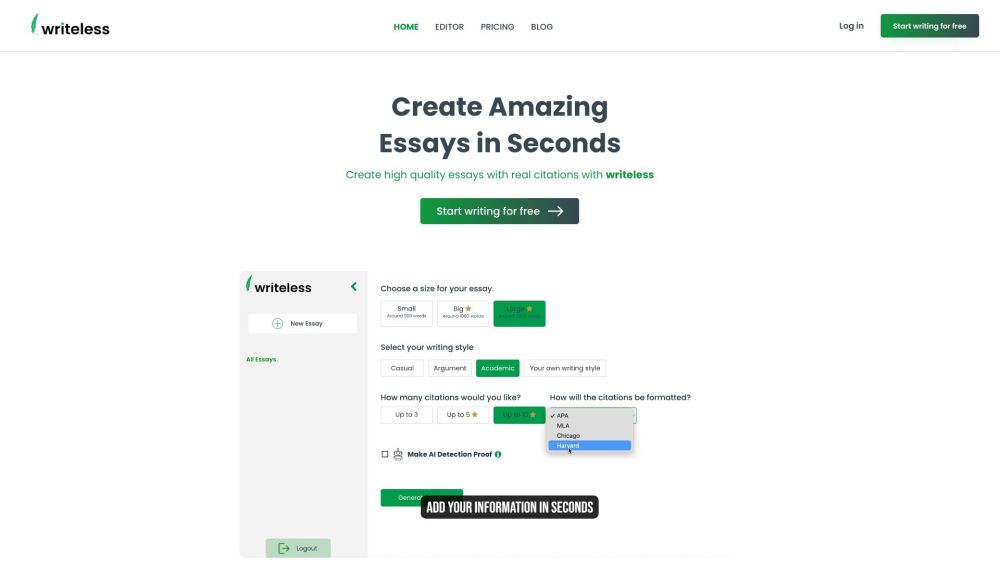
Desbloqueie o poder da redação de ensaios com IA, utilizando citações autênticas. Aprimore seu trabalho acadêmico com ferramentas avançadas de IA projetadas para gerar ensaios de alta qualidade apoiados por fontes confiáveis. Eleve sua escrita, economize tempo e garanta precisão com citações seguras ao seu alcance.
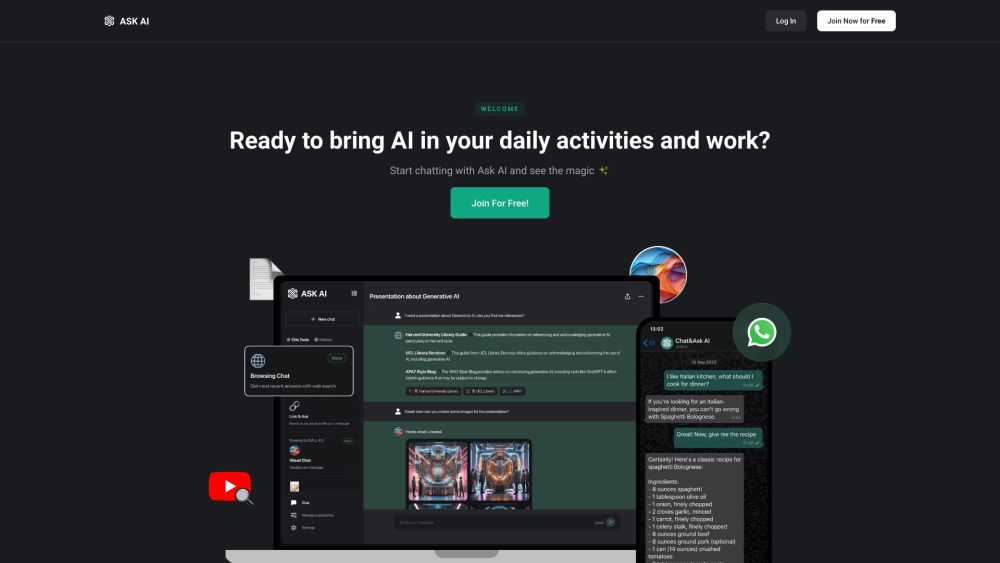
Descubra um assistente virtual inteligente com chatbot alimentado por IA, projetado para respostas instantâneas e suporte à escrita. Se você precisa de informações rápidas ou de ajuda para aprimorar seus textos, nosso chatbot inteligente está à disposição para auxiliá-lo a qualquer momento. Experimente a conveniência de ter um assistente virtual confiável que atende às suas necessidades!
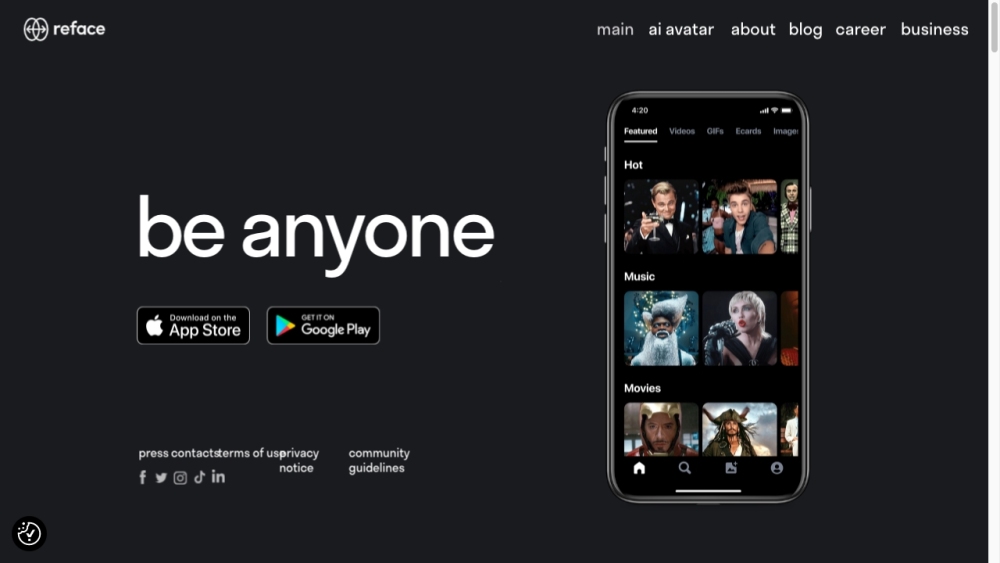
Transforme seus vídeos e GIFs com o aplicativo Reface movido por IA, que permite trocar rostos de forma fluida. Além disso, transforme suas fotos favoritas em divertida e vibrante cartoon com facilidade!
Find AI tools in YBX
Related Articles
Refresh Articles