Google Lança Versões Flash e Pro do Gemini 1.5 com Limite de 2 Milhões de Tokens para Acesso Público
Most people like

Descubra o poder de um gerador de música por IA que cria composições musicais de alta qualidade com facilidade. Seja você um músico experiente em busca de inspiração ou um iniciante querendo explorar sua criatividade, essa tecnologia de ponta permite que você crie músicas únicas e de nível profissional, adaptadas à sua visão. Libere seu potencial artístico com nosso inovador gerador de música por IA hoje mesmo!
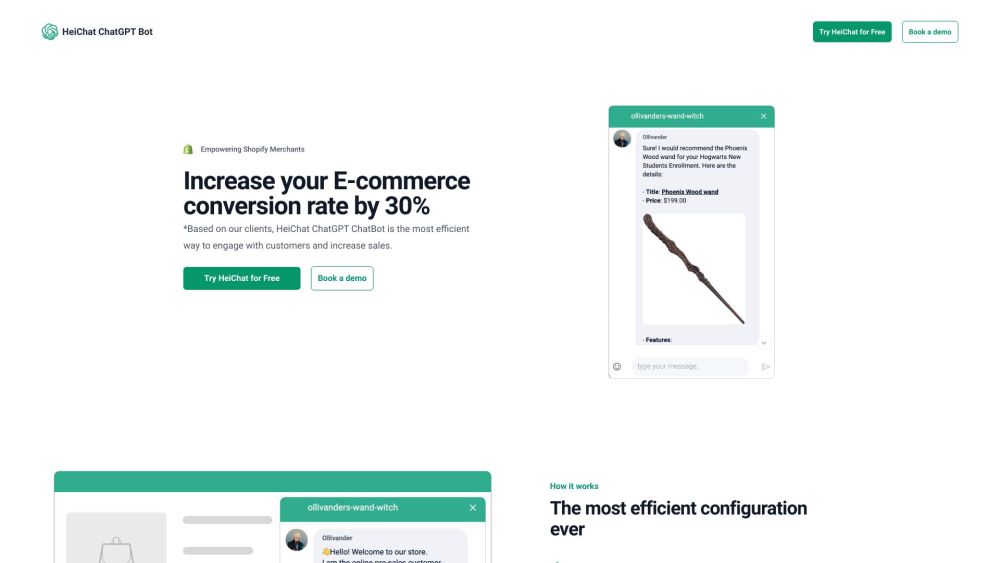
Descubra o HeiChat, um plugin de chatbot de ponta projetado especificamente para o setor de e-commerce. Ele se integra perfeitamente a diversas plataformas e suporta vários idiomas para aprimorar a interação com os clientes e impulsionar as vendas.
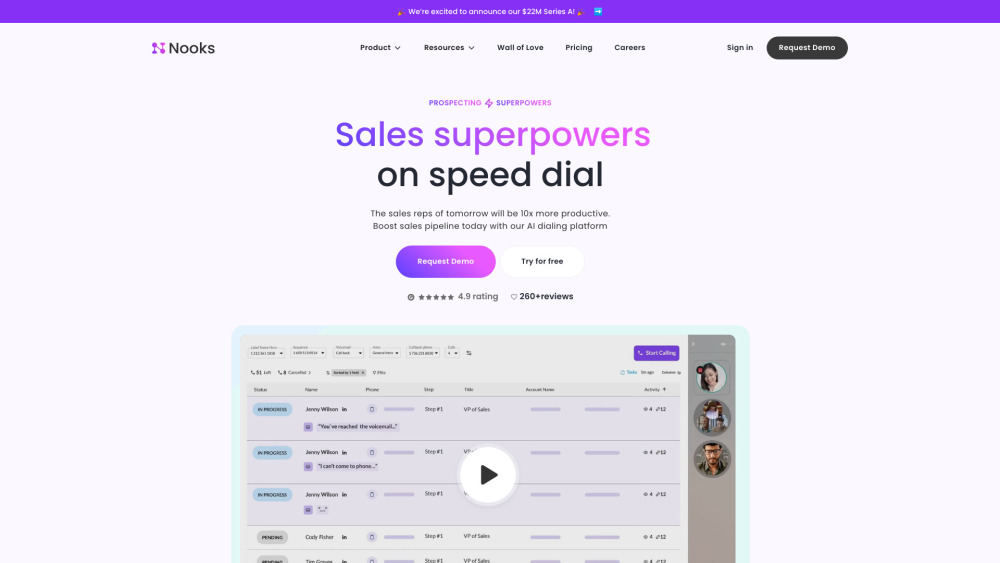
No ambiente de negócios acelerado de hoje, maximizar a produtividade de vendas é essencial para o sucesso. Uma plataforma de produtividade de vendas impulsionada por IA utiliza tecnologia avançada para otimizar processos de vendas, melhorar o desempenho da equipe e impulsionar o crescimento da receita. Ao automatizar tarefas repetitivas, fornecer insights valiosos e facilitar um melhor engajamento com os clientes, essa solução inovadora capacita as equipes de vendas a se concentrarem no que fazem de melhor—fechar negócios. Junte-se a nós enquanto exploramos como a integração da IA na sua estratégia de vendas pode transformar sua abordagem à produtividade e proporcionar resultados mensuráveis.
Desbloqueando a Inteligência Espacial Precisa com Soluções Geoespaciais Habilitadas por IA
Descubra como soluções geoespaciais inovadoras impulsionadas por IA estão transformando a inteligência espacial. Ao aproveitar algoritmos avançados e análises de dados, essas soluções oferecem precisão e insights sem igual, capacitando as indústrias a tomarem decisões informadas com base em dados geográficos precisos. Envolva-se com o futuro da análise espacial e aprofunde sua compreensão das complexidades do nosso mundo.
Find AI tools in YBX
