Modelos de IA Avaliam Sua Própria Segurança: Insights da Mais Recente Pesquisa de Alinhamento da OpenAI
Most people like
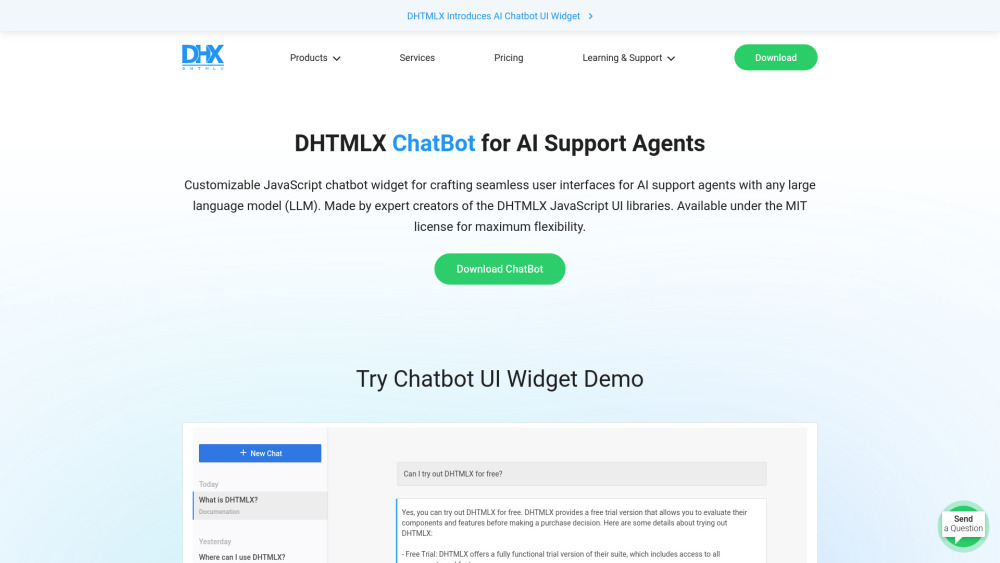
Desbloqueie interações sem complicações com nosso inovador Widget de Chatbot, projetado especificamente para agentes de suporte por IA. Esta poderosa ferramenta melhora a experiência do usuário ao fornecer assistência instantânea, resolver dúvidas e aumentar o engajamento geral. Transforme seu atendimento ao cliente com um suporte eficiente baseado em IA que eleva a satisfação enquanto otimiza as operações. Abrace o futuro da comunicação com o cliente e descubra como nosso Widget de Chatbot pode revolucionar sua estratégia de suporte hoje mesmo!
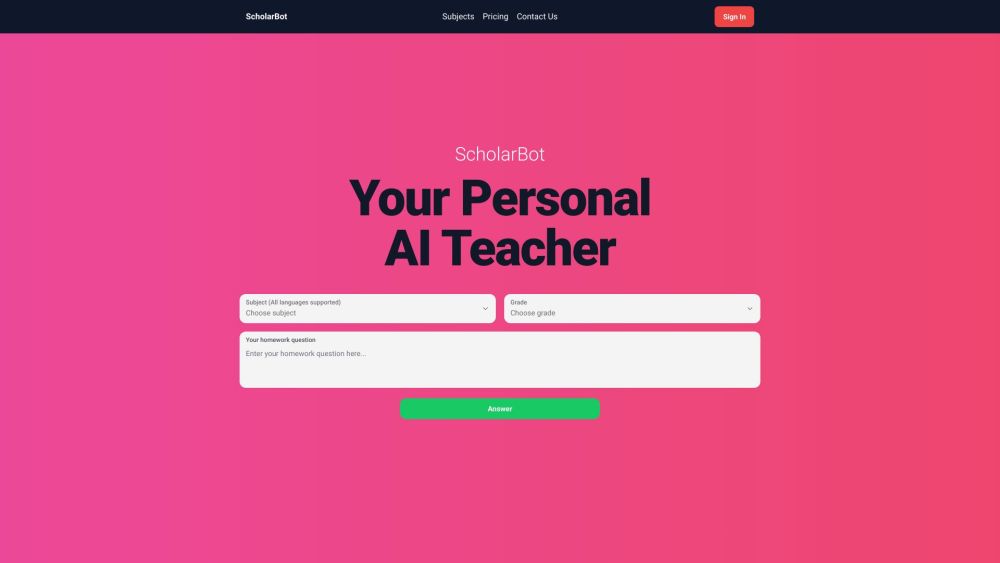
Desbloqueie uma aprendizagem mais inteligente com nosso resolvedor de tarefas impulsionado por IA. Transformando a maneira como os estudantes se envolvem com seus estudos, essa ferramenta inovadora utiliza inteligência artificial para oferecer assistência instantânea e aprimorar a compreensão. Eleve sua jornada acadêmica e descubra uma forma mais eficiente de enfrentar tarefas e aumentar suas notas hoje mesmo!
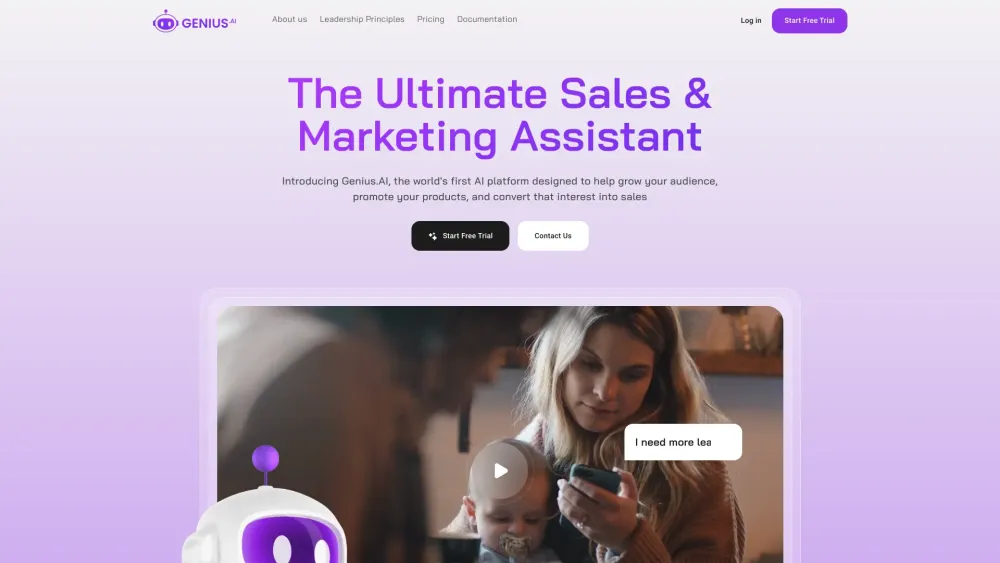
No cenário digital de hoje, aproveitar a Inteligência Artificial em Mídias Sociais é fundamental para impulsionar estratégias de vendas e marketing bem-sucedidas. Essa tecnologia inovadora permite que as empresas analisem o comportamento do consumidor, otimizem o direcionamento de campanhas e agilizem os esforços de engajamento. Ao integrar soluções de IA, as marcas podem desbloquear insights valiosos, criar experiências personalizadas e, em última análise, aumentar as taxas de conversão. Descubra como a Inteligência Artificial em Mídias Sociais pode transformar suas abordagens de vendas e marketing para se manter à frente da concorrência.
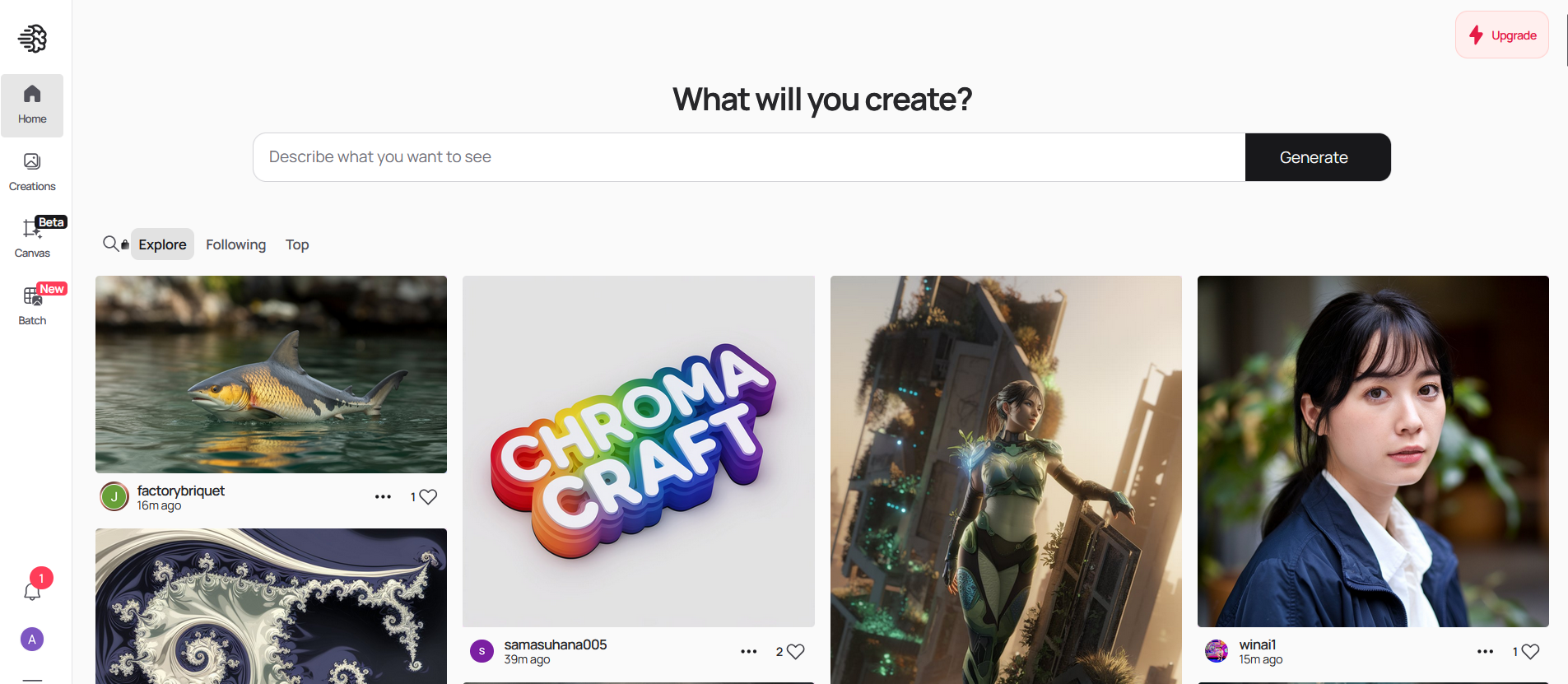
O Ideogram é uma ferramenta de IA gratuita que gera imagens realistas, pôsteres, logotipos e muito mais.
Find AI tools in YBX
Related Articles
Refresh Articles