MIT и Cohere объединили силы для запуска платформы по отслеживанию и фильтрации проверенных наборов данных для ИИ.
Most people like
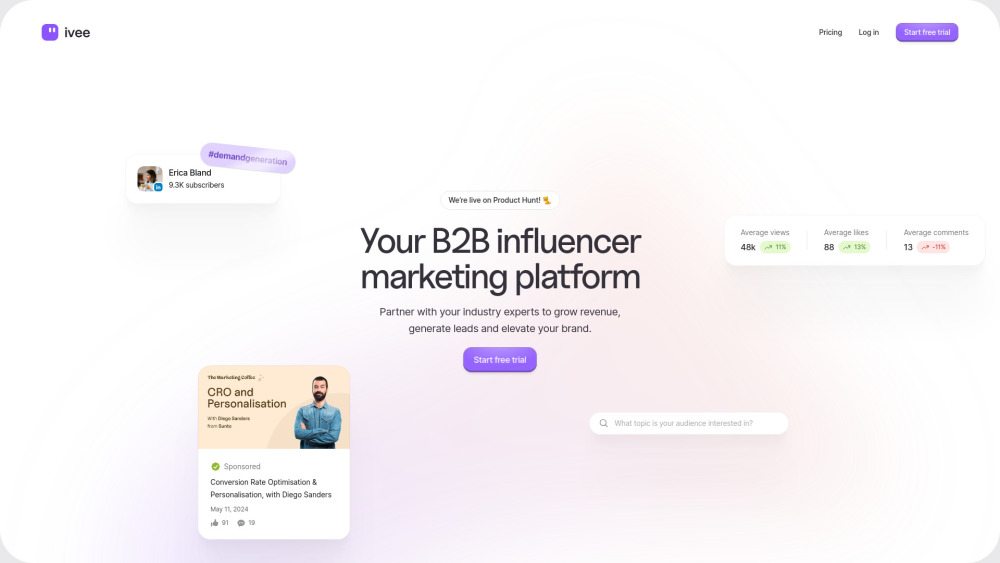
В сегодняшнем цифровом ландшафте платформы B2B-инфлюенсер-маркетинга стали мощными инструментами для бизнеса, стремящегося повысить видимость и доверие к своему бренду. Сотрудничая с лидерами отрасли и инфлюенсерами, компании могут эффективно взаимодействовать с целевой аудиторией, строить доверие и повышать конверсии. Эта статья рассматривает ключевые преимущества и стратегии использования платформ B2B-инфлюенсер-маркетинга для улучшения ваших маркетинговых усилий и достижения устойчивого роста. Узнайте, как эти платформы могут изменить ваш подход к привлечению клиентов и генерации лидов на конкурентном рынке.
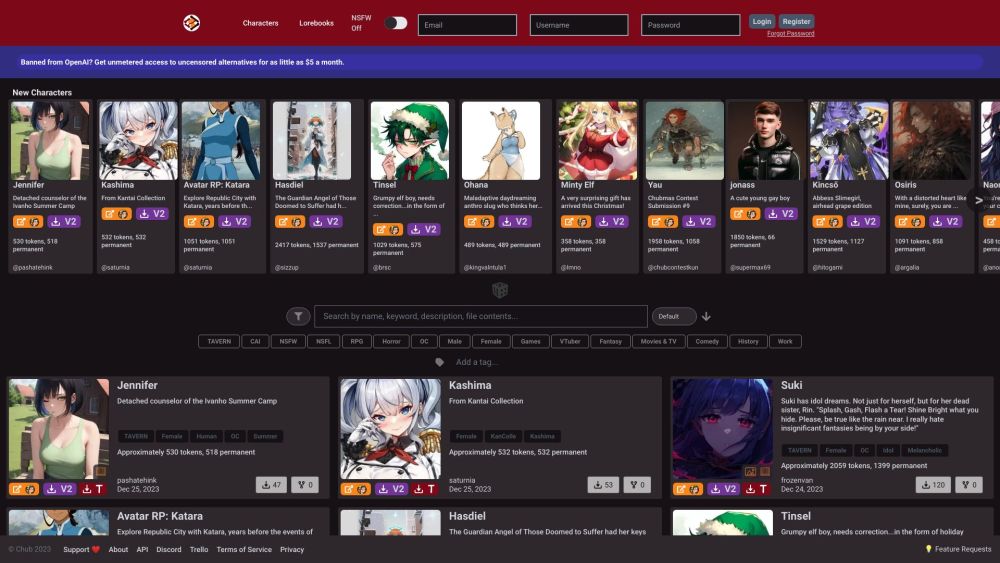
Раскройте весь потенциал своих языковых моделей, эффективно управляя и сотрудничая в разработке персонажей. Независимо от того, создаете ли вы интерактивные истории, разрабатываете уникальные образы или обучаете ИИ понимать разнообразные голоса, мастерство управления персонажами является ключом к достижению реалистичных и увлекательных результатов.

Denvr Dataworks специализируется на предоставлении надежных облачных и инфраструктурных решений, адаптированных для искусственного интеллекта (ИИ), машинного обучения (МО), высокопроизводительных вычислений (ВПВ) и различных вычислительных приложений.
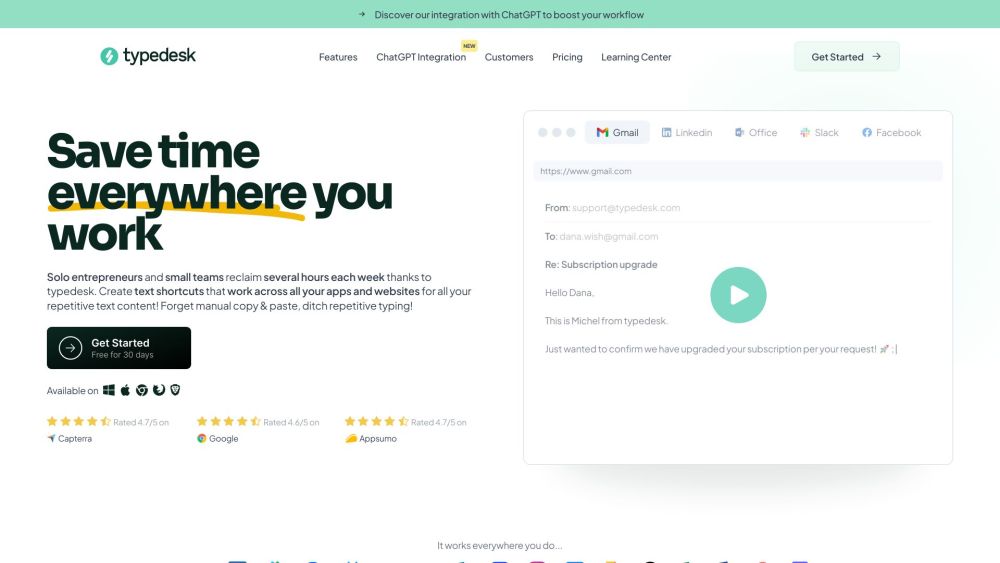
Typedesk — это мощное универсальное приложение, разработанное для автоматизированного ввода текста, повышая согласованность на разных платформах. С Typedesk упростите свой рабочий процесс и повысите продуктивность без усилий.
Find AI tools in YBX
Related Articles
Refresh Articles