Как OpenAI и Meta используют видео на YouTube для обучения ИИ: взгляд на новые тенденции в индустрии
Most people like
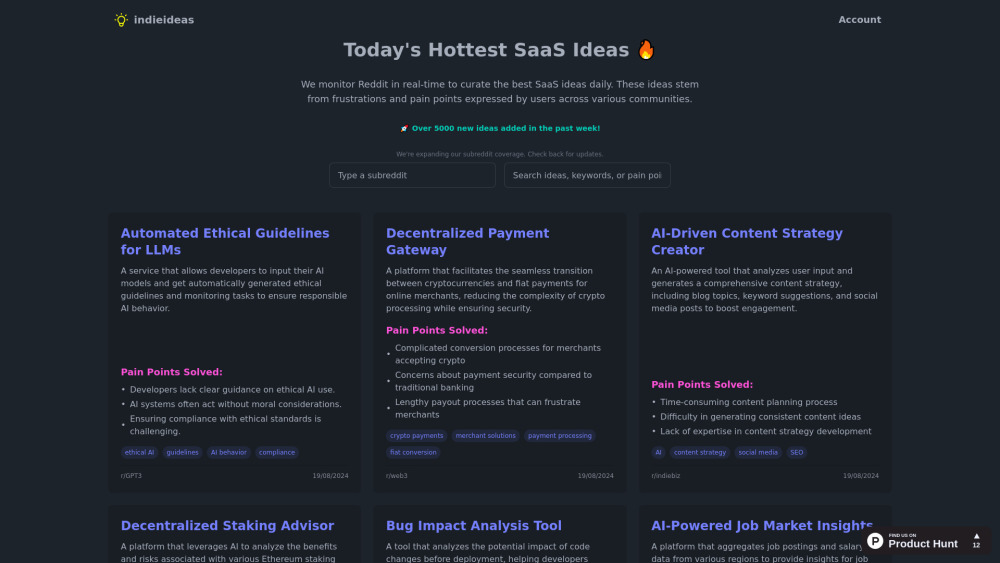
Откройте для себя инновационные SaaS-решения, вдохновленные ежедневными проблемами пользователей Reddit.

Повышение пасторской эффективности с помощью ИИ для безуспешной подготовки проповедей.
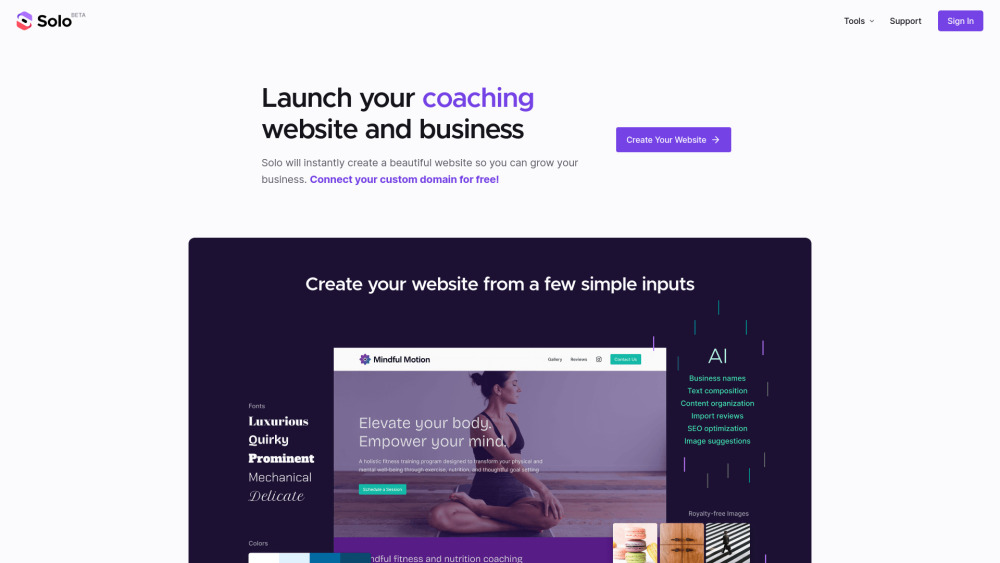
В современном цифровом мире наличие яркого онлайн-присутствия имеет решающее значение для бизнеса любого размера. Создатель веб-сайтов на основе ИИ упрощает процесс создания профессионального сайта, позволяя предпринимателям и компаниям легко разрабатывать впечатляющие ресурсы. Используя передовые технологии, эти инструменты предлагают настраиваемые шаблоны и удобные интерфейсы, давая возможность пользователям установить свою бренд-идентичность и повысить вовлеченность клиентов. Узнайте, как создатель веб-сайтов на базе ИИ может преобразовать вашу бизнес-стратегию и способствовать успеху в интернете.
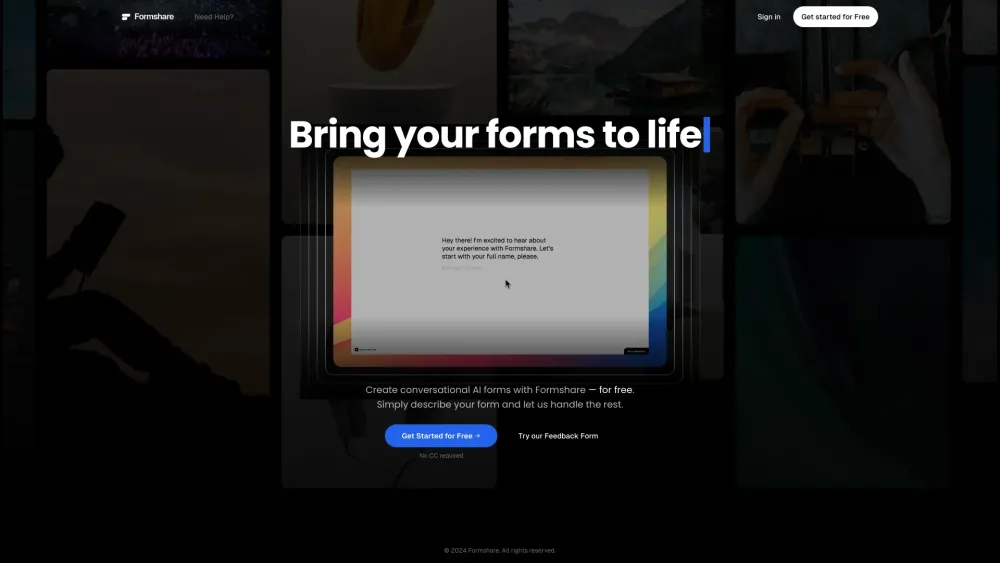
В современном цифровом мире возможность быстро создавать настроенные формы имеет решающее значение для бизнеса. С помощью современных инструментов ИИ вы можете легко разрабатывать интеллектуальные формы без знаний программирования. Этот удобный подход позволяет всем — от предпринимателей до маркетологов — оптимизировать сбор данных и улучшить пользовательский опыт, экономя время и ресурсы. Узнайте, как создание форм на основе ИИ упрощает вашу работу и повышает качество ваших проектов, делая это доступным для всех, независимо от уровня технических навыков.
Find AI tools in YBX
Related Articles
Refresh Articles