Разблокировка GPT-4: удивительная производительность в офтальмологической оценке и экспертные рекомендации по осторожному внедрению.
Most people like
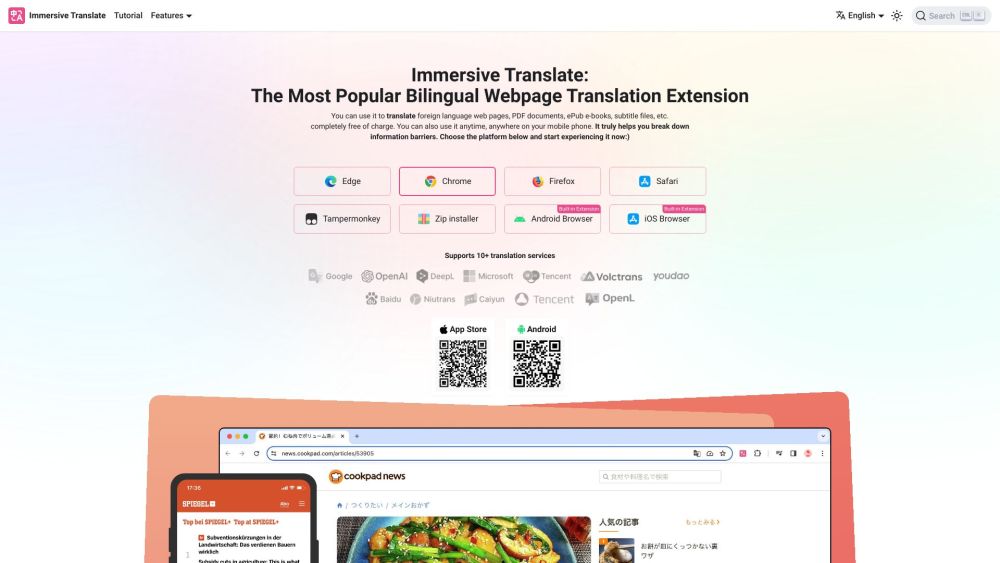
Представляем наш бесплатный двуязычный инструмент для перевода веб-страниц и документов, созданный для упрощения процесса перевода и повышения доступности. Независимо от того, нужно ли вам перевести контент сайта или важные документы, наша интуитивно понятная платформа обеспечивает ясное общение на нескольких языках, позволяя вам легко взаимодействовать с глобальной аудиторией. Переводите с легкостью и улучшайте свое онлайн-присутствие уже сегодня!
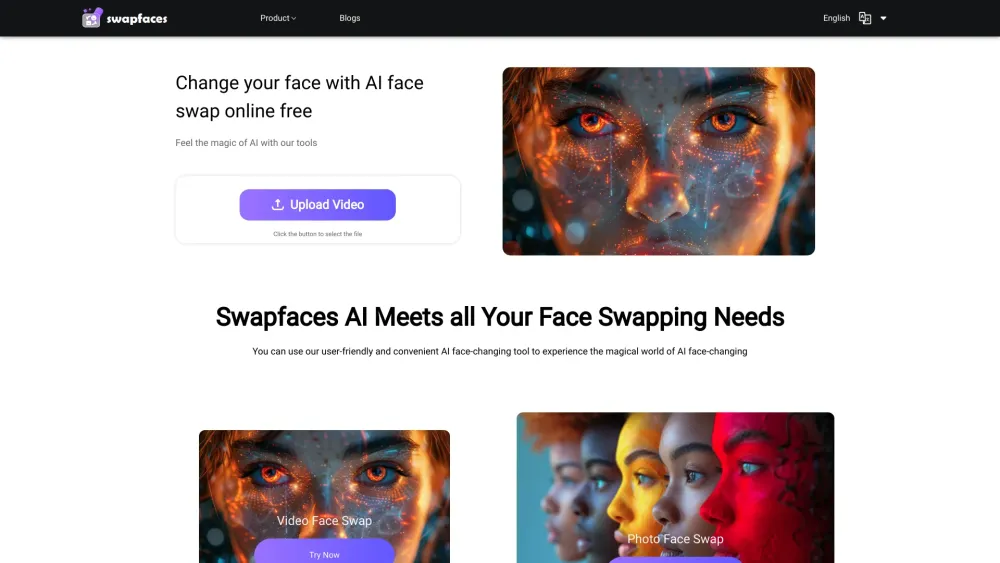
Откройте для себя захватывающий мир замены лиц с помощью ИИ — передовой технологии, позволяющей легко менять лица на фотографиях и видео. Этот инновационный инструмент использует современные алгоритмы искусственного интеллекта для создания безупречных и реалистичных переходов, позволяя вам преобразовывать визуальный контент всего за несколько кликов. Независимо от того, хотите ли вы улучшить свои публикации в соцсетях, создать интересные мемы или поэкспериментировать с креативными проектами, технологии замены лиц на основе ИИ открывают бесконечные возможности для персонализации и развлечения. Погрузитесь в будущее визуального редактирования уже сегодня!

Превратите обычные фотографии в профессиональные снимки с помощью технологии искусственного интеллекта.
Find AI tools in YBX
Related Articles
Refresh Articles