Anthropic запускает Claude 3: ИИ с возможностями, приближающимися к человеческому уровню, на фоне усиливающейся конкуренции.
Most people like
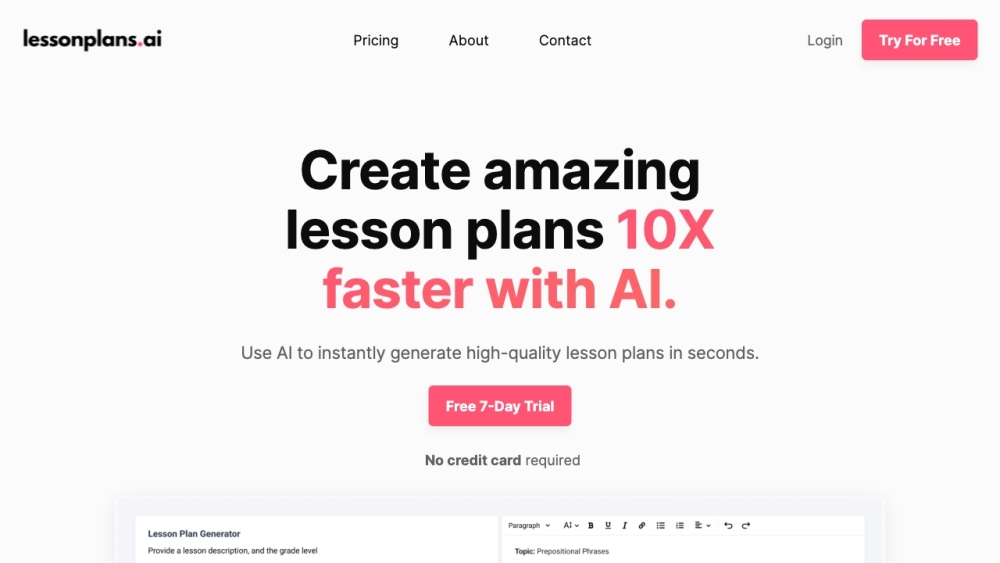
Откройте для себя LessonPlans.ai — инновационную платформу с поддержкой ИИ, разработанную для создания качественных, индивидуализированных планов уроков для учителей. Идеальный инструмент для педагогов, стремящихся улучшить свой учебный процесс, LessonPlans.ai упрощает планирование уроков, экономя время и усилия, обеспечивая при этом увлекательный и эффективный опыт обучения.

Раскройте потенциал передовой технологии распознавания изображений с нашим мощным API, предназначенным для эффективного тегирования, бесшовной категоризации и точного распознавания лиц. Независимо от того, хотите ли вы улучшить свои приложения или оптимизировать процесс обработки изображений, наш API предоставляет инструменты, необходимые для повышения пользовательских впечатлений и улучшения организационной эффективности. Преобразуйте управление визуальным контентом с помощью современных решений, адаптированных к вашим уникальным потребностям.
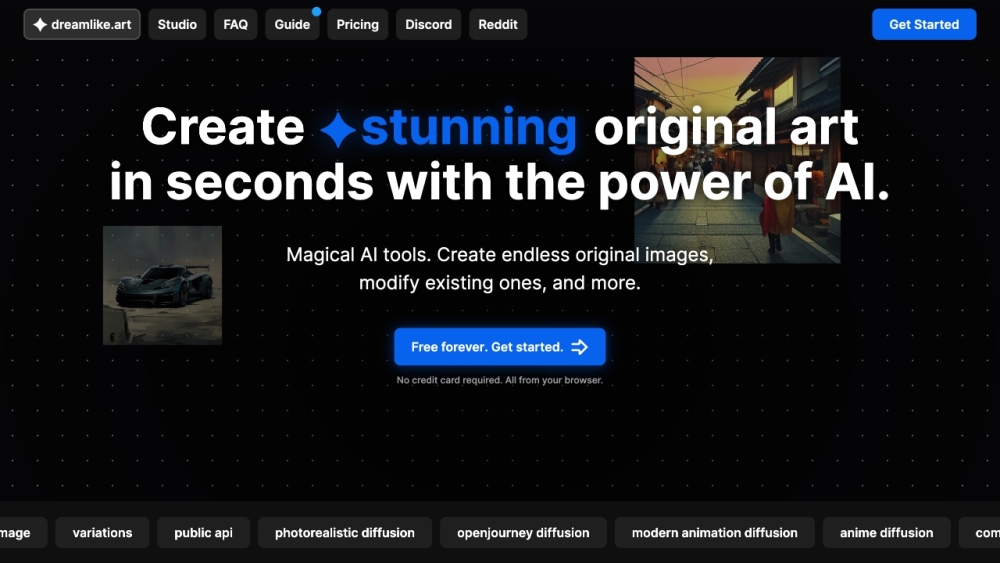
Преобразуйте свое творческое видение в потрясающие произведения искусства всего за считанные секунды с помощью Stable Diffusion — бесплатного генератора искусственного интеллекта для художников и энтузиастов.

В стремительно развивающейся области искусственного интеллекта, большие китайские языковые модели для общения находятся на передовом крае инноваций. Эти продвинутые системы созданы для понимания и генерации текстов, схожих с человеческими, что обеспечивает беспрепятственное общение на мандаринском. Поскольку предприятия и отдельные пользователи все чаще ищут эффективные способы взаимодействия и обмена информацией, эта технология трансформирует клиентский сервис, создание контента и многое другое. Узнайте, как эти мощные модели могут улучшить общение и способствовать более глубоким связям в цифровую эпоху.
Find AI tools in YBX
Related Articles
Refresh Articles