Meta的多標記預測將人工智慧模型速度提升至最高3倍
Most people like

透過我們的雲端圖像創建平台,顛覆您的創意過程,激發您的藝術潛能。無論您是專業平面設計師或熱愛創作的愛好者,我們直觀的工具和功能都能讓您輕鬆打造驚豔的視覺作品。加入創意社群,從雲端便利中探索數位設計的無限可能性。今天就輕鬆提升您的項目!
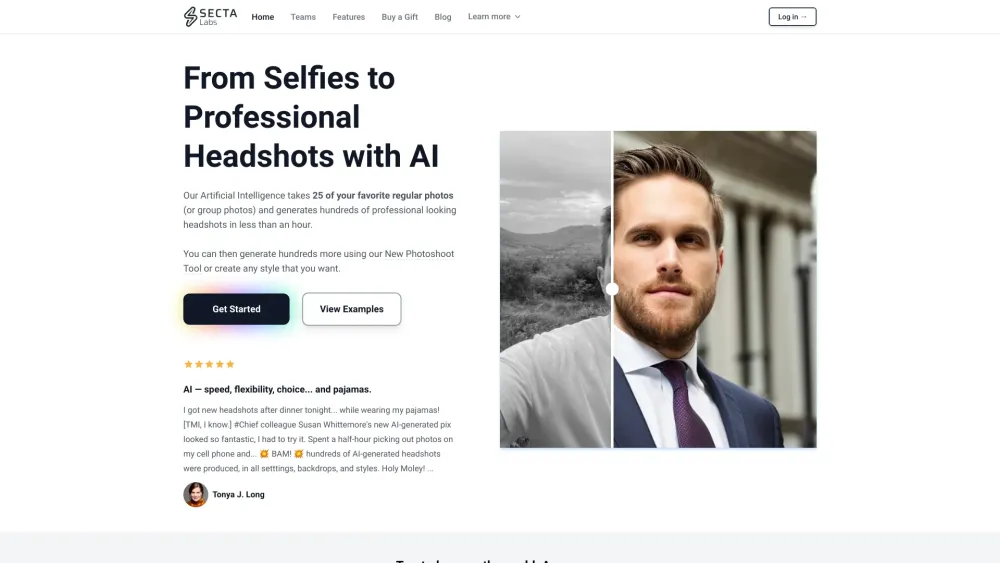
在當今的數位世界,良好的第一印象至關重要。 AI 生成的專業頭像不僅提升您的線上形象,還傳達出專業性和親和力。這些頭像利用先進的人工智慧技術,專為個人和企業的獨特風格及品牌需求而打造。了解如何擁抱 AI 生成的影像,能夠改變您的個人和專業品牌,讓您在競爭激烈的環境中脫穎而出。
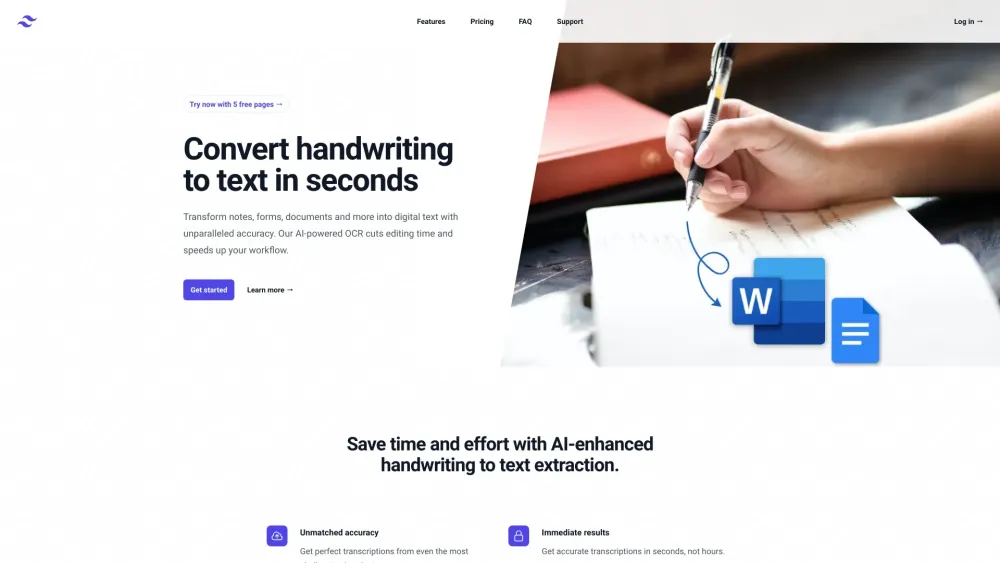
以精確度將手寫內容轉換為數位格式
在當今快速發展的數位世界中,將手寫內容轉換為數位格式變得愈加重要。無論您是想保留筆記、將草圖轉化為數位圖形,或是簡化文件處理,準確數位化手寫材料對於提升效率和可及性至關重要。善用科技的力量,讓您的手寫內容輕鬆可搜尋、可編輯和易於分享,確保您珍貴的資訊隨時可用。
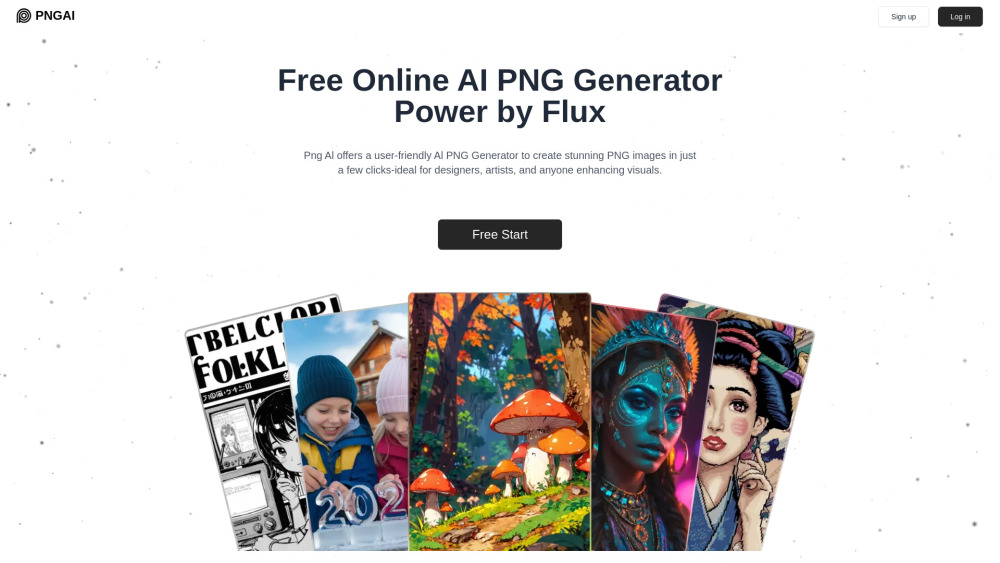
探索一款免費的AI工具,能瞬間輕鬆生成高品質的PNG圖片。這個創新的解決方案讓您能迅速而輕鬆地創作驚艷的視覺效果,完美提升您的項目。無論是個人使用還是專業設計,今天就用這個強大的資源來提升您的創意吧!
Find AI tools in YBX
Related Articles
Refresh Articles