OpenAI 揭示全新開發者大會格式:不計劃發布 GPT-5
Most people like
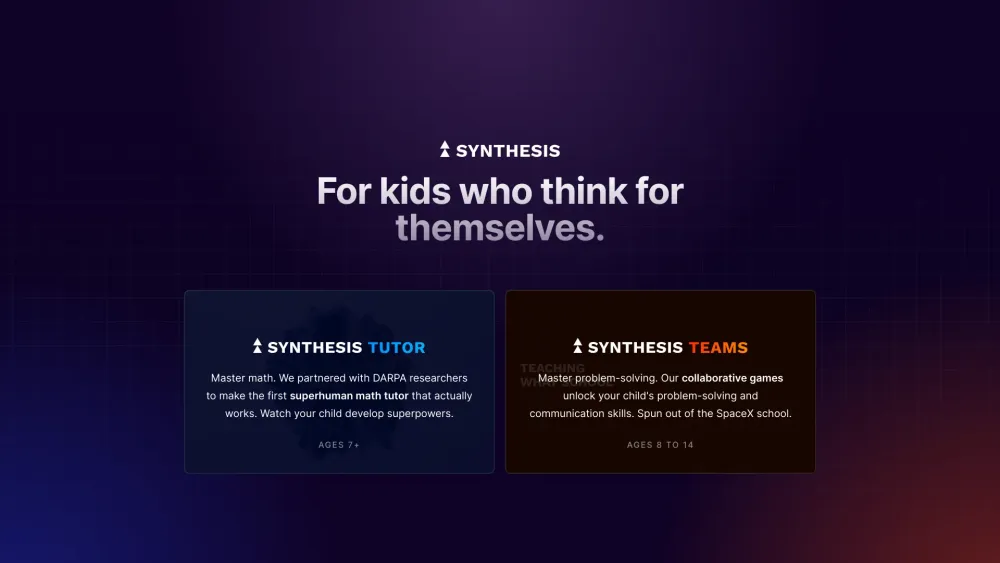
在當前快速變化的數位環境中,有效的教育人工智慧正在改變我們的學習和教學方式。透過利用先進的演算法和數據驅動的見解,基於人工智慧的解決方案增強了個性化學習體驗,提升了學生的參與度,並簡化了管理流程。本文探討了教育人工智慧對現代教育的深遠影響,強調其優勢和顛覆學習環境的潛力。加入我們,深入探討教育科技的未來及其在促進更好教育方面的角色。
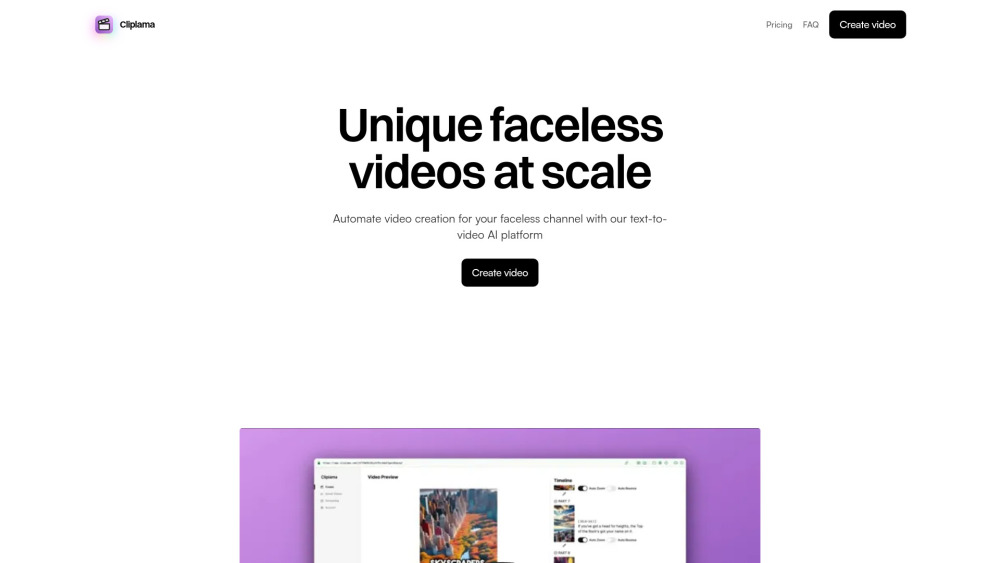
簡化您的社交媒體策略,透過自動化影片製作。 在當今迅速變化的數位環境中,吸引人的影片內容對於抓住觀眾的注意力至關重要。自動化工具徹底改變了您製作影片的方式,使分享引人入勝的故事、展示產品和與追隨者連結變得更簡單更快速。無論您是希望增強線上形象的品牌,還是希望擴大影響力的個人創作者,都能發現自動化影片製作如何提升您的社交媒體表現。
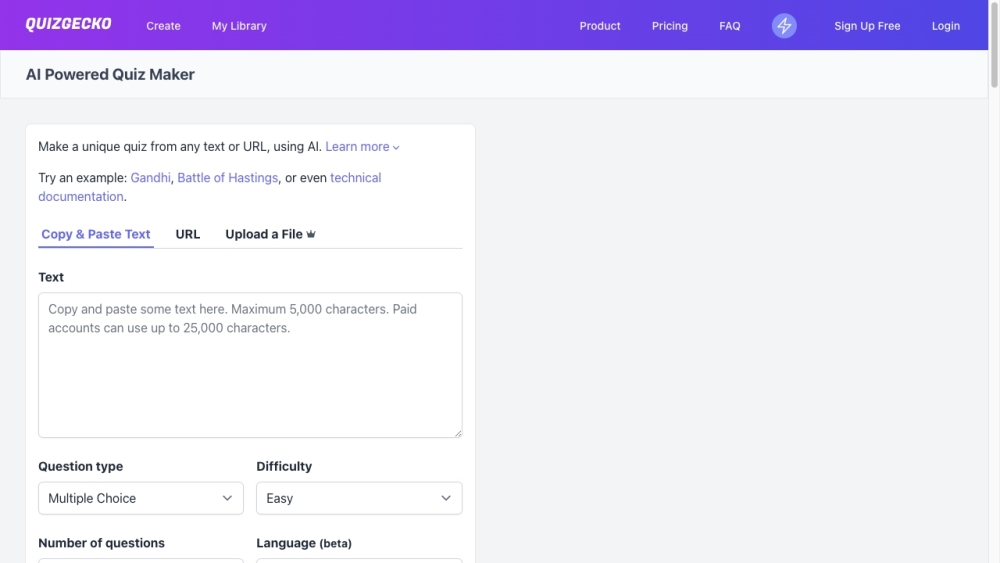
Quizgecko 是一個創新的人工智慧驅動平台,旨在根據您現有的內容創建引人入勝的測驗。無論您是教育工作者、市場營銷專家還是內容創作者,Quizgecko 都能將您的素材轉化為互動測驗,增強學習效果和參與度。探索人工智慧在測驗生成中的強大功能,立即提升您的內容!
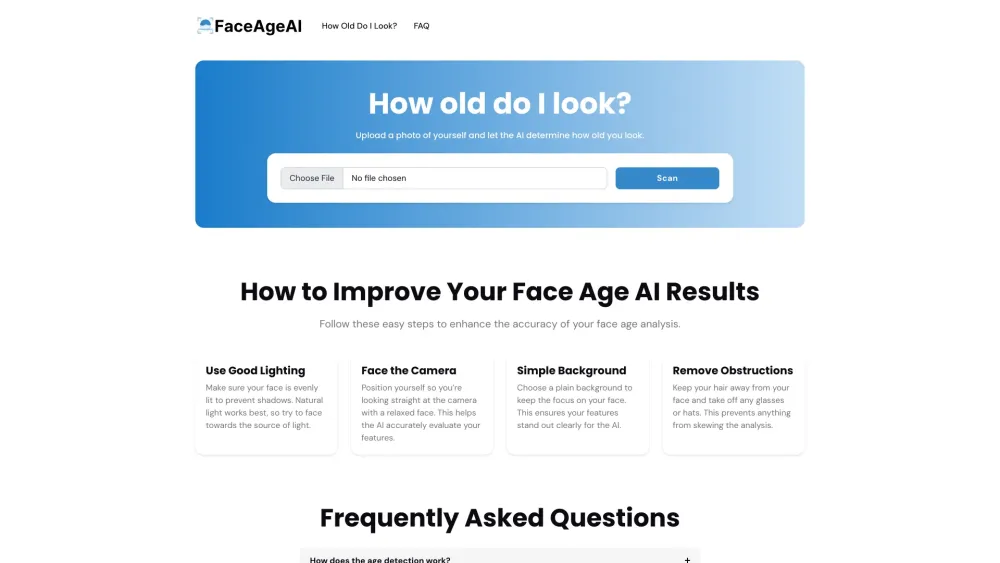
Find AI tools in YBX
Related Articles
Refresh Articles