Stable Audio Open:Stable AI的開源音頻生成模型,為音頻創作提供全新選擇
Most people like
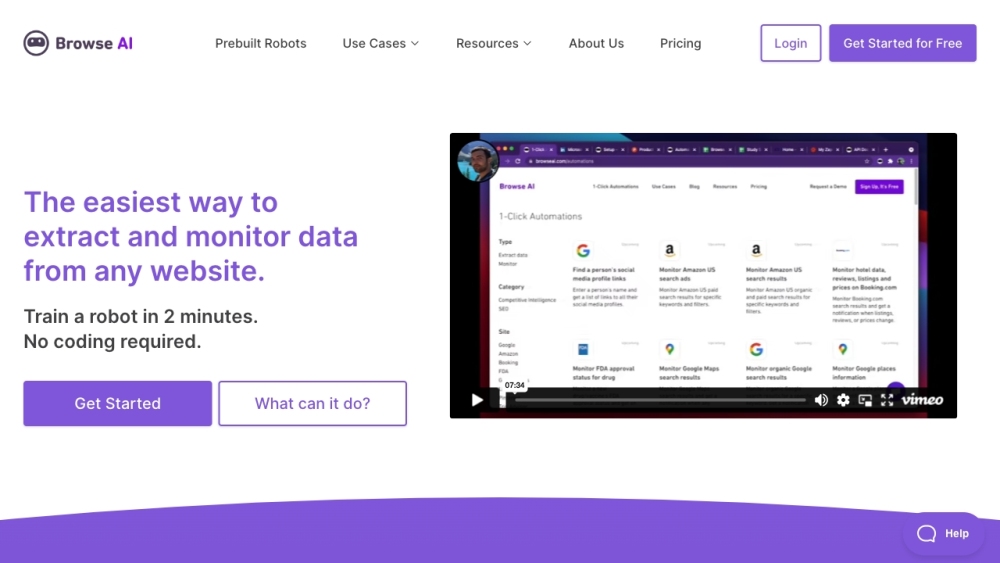
Browse AI是一個直觀的網頁自動化平台,旨在實現無縫的數據擷取和實時監控。無論您需要從網站收集數據還是跟踪變化,Browse AI都能簡化過程,使每個人都能輕鬆使用。

Find AI tools in YBX
Related Articles

Refresh Articles