人類提示強化學習:一種修正人工智慧系統錯誤的創新方法
Most people like
介紹一個專為生成式人工智能應用而設計的雲端平台。此創新解決方案利用雲端的力量來簡化流程、提升創意並推動人工智能開發的效率。探索我們的平台如何轉變您的項目,並在生成式人工智能領域釋放新可能性。
在當今快速變化的商業環境中,工業生成式人工智慧正在徹底改變企業解決方案。透過先進的算法和機器學習,組織能提升生產力、驅動創新並優化運營。這種變革性技術使企業能夠創造符合其特定需求的定制解決方案,從而促進更智能的決策並在競爭激烈的市場中促進增長。擁抱未來的工業生成式人工智慧,探索它如何重新定義您的企業戰略。

發掘最佳的 ChatGPT 替代方案,提升您的 AI 聊天能力!與先進的聊天解決方案進行互動,增強您的交流體驗,這些方案專為滿足您的需求而設計。不論您是在尋找創新功能或卓越性能,探索這些強大的選擇,讓互動變得更具變革性。
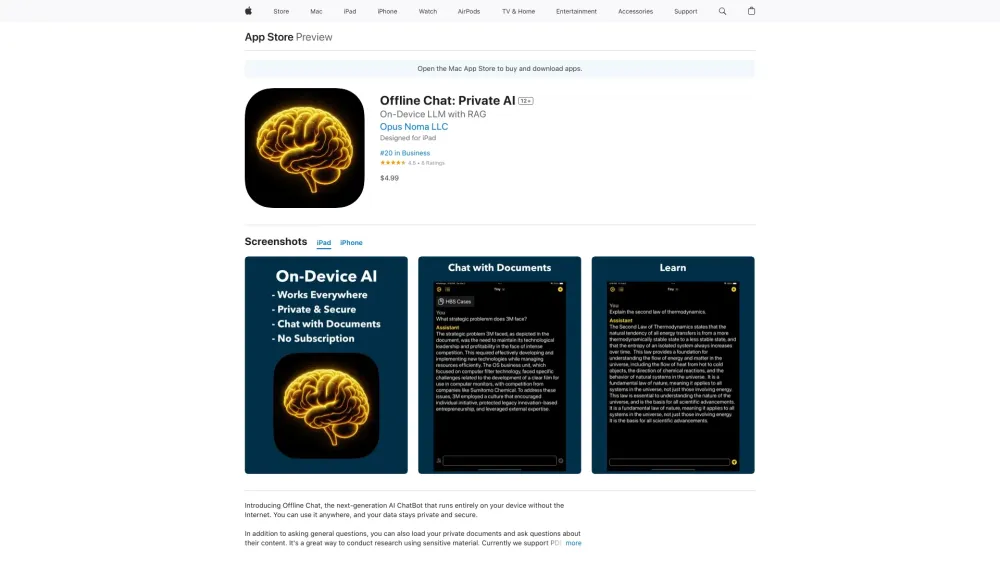
在當今的數位環境中,裝置內大型語言模型(LLMs)與檢索增強生成(RAG)技術的整合代表了人工智慧的一項重大突破。這種創新方法不僅提升了 AI 系統的能力,還確保它們在邊緣高效運行,最小化延遲並最大化性能。在我們探索裝置內處理與 RAG 的交集時,您將發現這種協同效應如何轉變用戶體驗,並推動各種應用中的智能解決方案。請與我們一起深入了解這項革命性技術!
Find AI tools in YBX
Related Articles
Refresh Articles