OpenAI SearchGPT 官方演示暴露漏洞:揭示源代码和搜索机制背后的秘密
Most people like
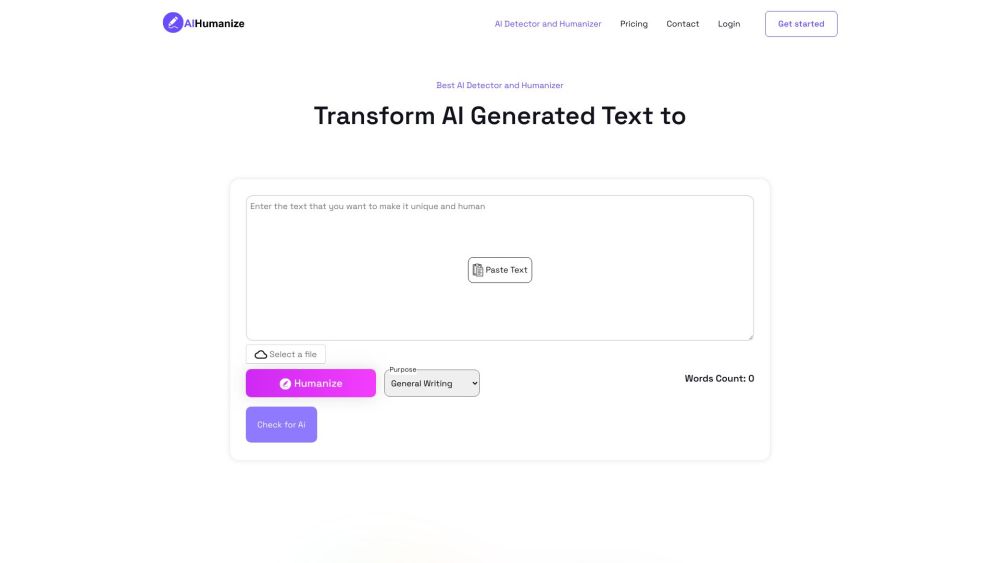
将AI文本转化为自然内容,为您的内容创作带来革命性的改变。随着人工智能的快速发展,越来越多的企业和创作者开始利用AI生成文本。然而,这些文本往往缺乏自然流畅的感觉和人性化的表达。在本文中,我们将探讨如何有效地将AI生成的文本转换为更自然、更具吸引力的内容,以提升读者的阅读体验和参与度。通过掌握这一技巧,您将能够在创作中融合AI的效率与人类的情感,从而制作出令人印象深刻的作品。
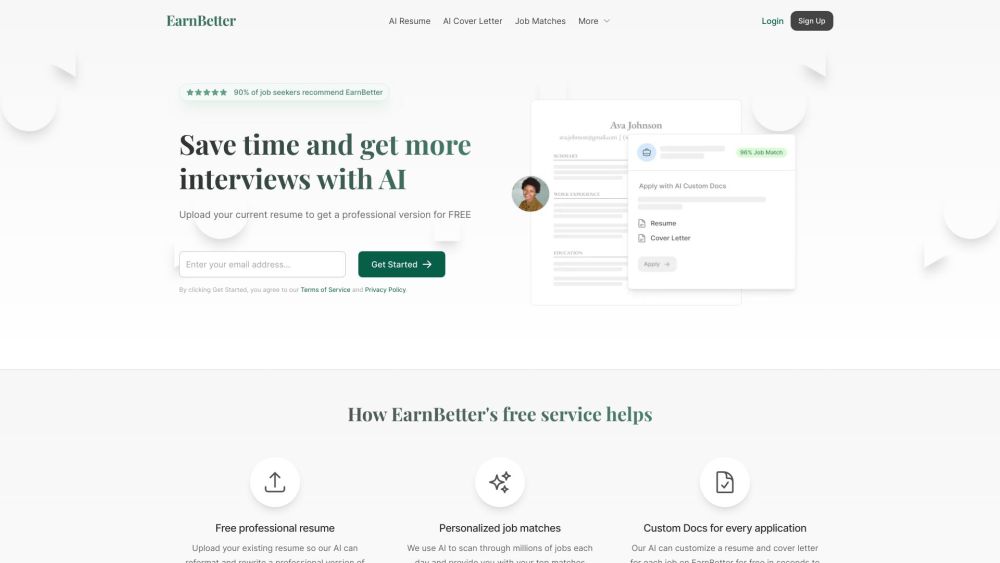
免费人工智能求职助手 - 在这个竞争激烈的职场中,我们的免费人工智能求职助手将全力支持您的求职之旅。无论您是刚踏入职场的新手,还是寻求职业发展的专业人士,我们的工具将帮助您获得最新的求职技巧、简历优化建议和面试准备指导。利用先进的AI技术,打造符合您个性和需求的求职策略,助您顺利获得梦寐以求的职位。
Find AI tools in YBX
Related Articles
Refresh Articles