OpenAI被指控未经授权抓取YouTube视频训练AI模型Sora:引发激烈争议
Most people like
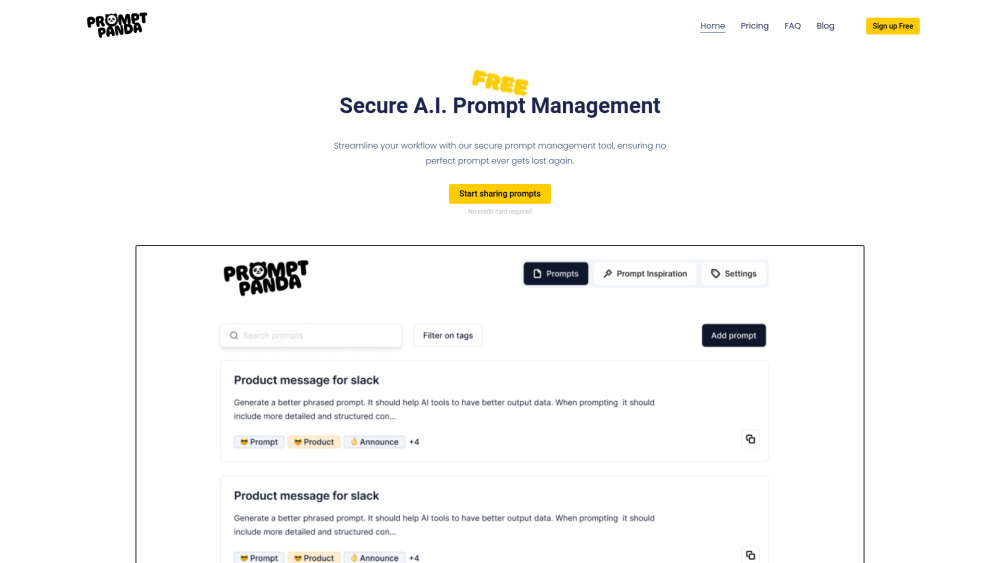
AI提示管理:提升工作效率与优化流程
在当今快速发展的数字时代,AI提示管理正成为优化工作流程的重要工具。通过智能化的提示和管理,企业能够提升团队的生产力,实现更高效的任务执行。本篇文章将深入探讨AI提示管理的优势,并提供实用的策略,以帮助您在工作中更好地利用这一创新技术。
Find AI tools in YBX
Related Articles
Refresh Articles