大型语言模型新漏洞曝光:Anthropic揭示扩展上下文窗口的弱点
Most people like

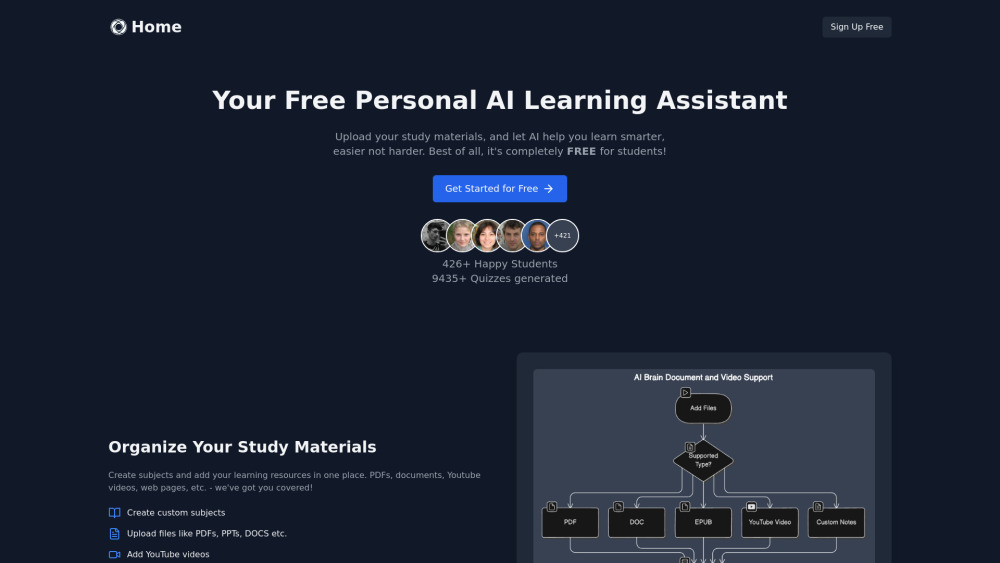
AI学习助手是一款智能工具,旨在帮助用户整理学习资料并创建测验。它通过分析用户的学习内容,提高学习效率,增强知识掌握。无论是学生还是自学者,AI学习助手都能提供个性化的学习支持。
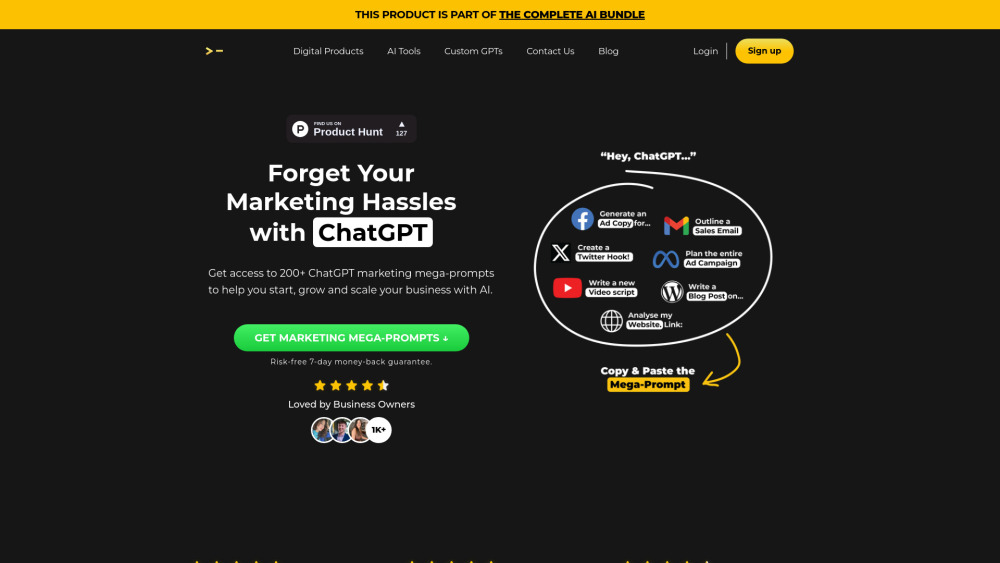
200+个ChatGPT超级提示,助您提升转化率,利用AI扩展品牌影响力。探索这些实用工具,激发您的营销潜力!
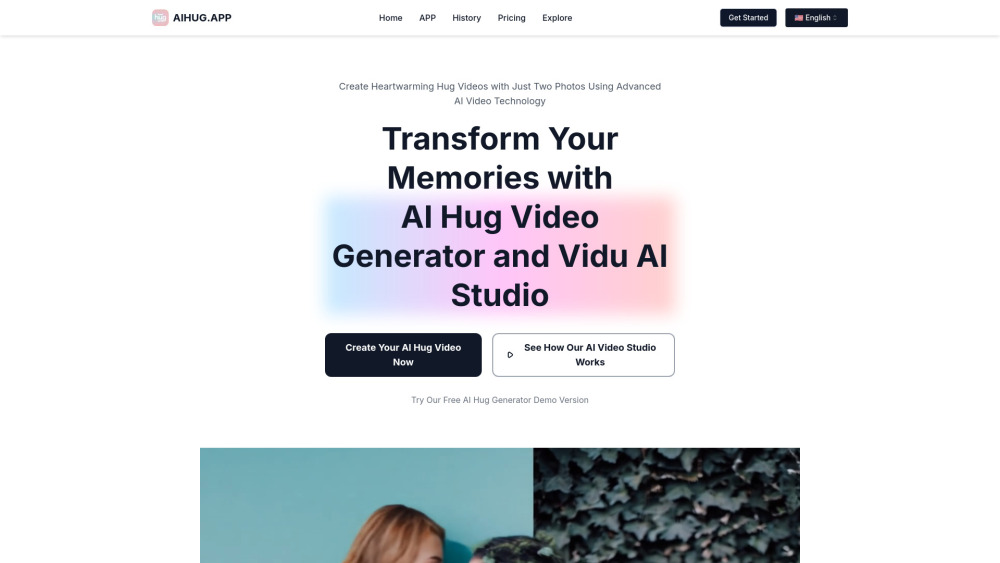
Find AI tools in YBX
Related Articles
Refresh Articles