探秘苹果新推出的“MM1”人工智能模型:功能、应用与创新
Most people like
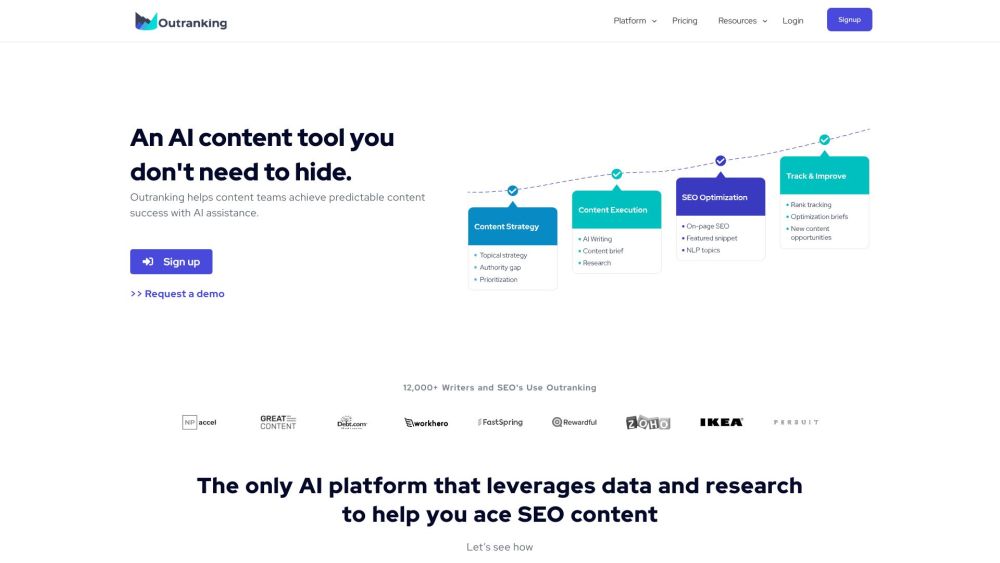

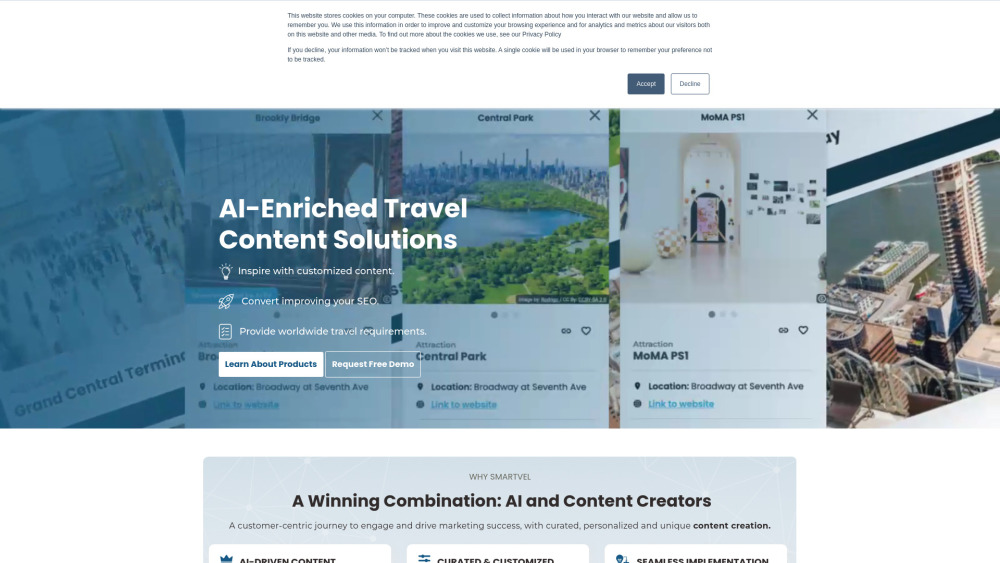
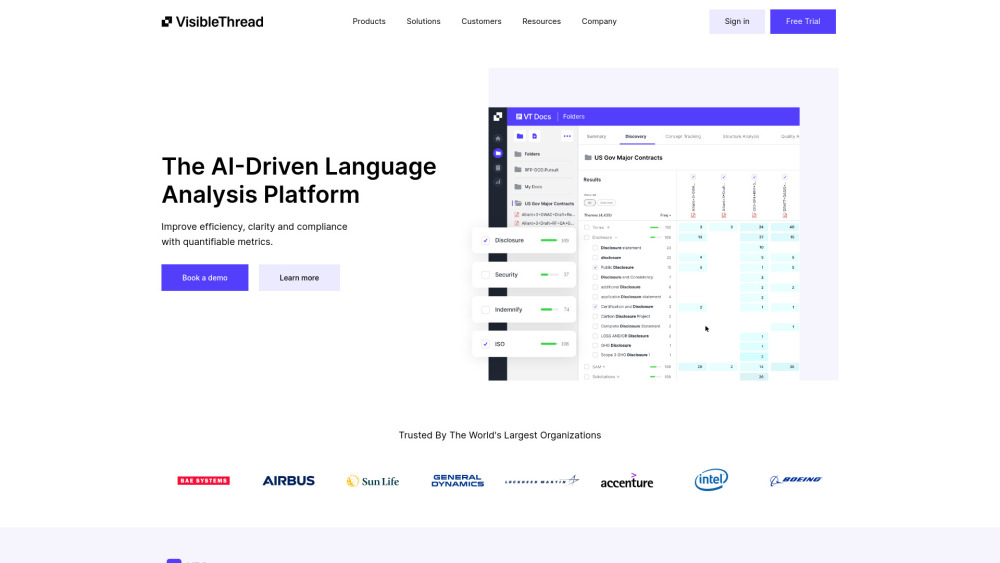
Find AI tools in YBX
Related Articles
Refresh Articles
Find AI tools in YBX