Amazon Investigates Perplexity AI Over Allegations of Unauthorized Website Scraping
Most people like
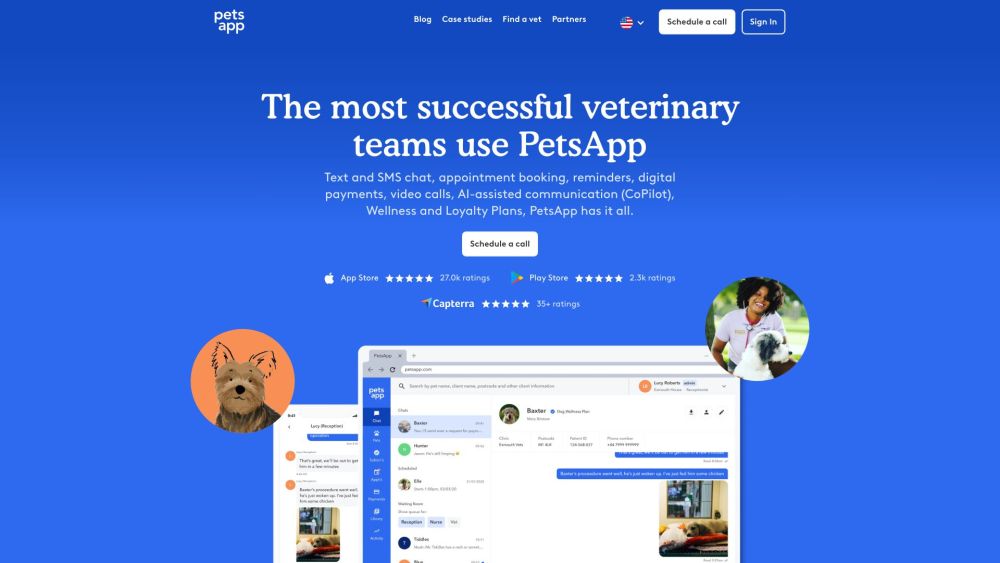
Introducing a comprehensive platform for veterinary engagement and communication, designed to enhance interactions within the veterinary community. This innovative solution streamlines communication and fosters collaboration among veterinarians, pet owners, and animal care professionals.
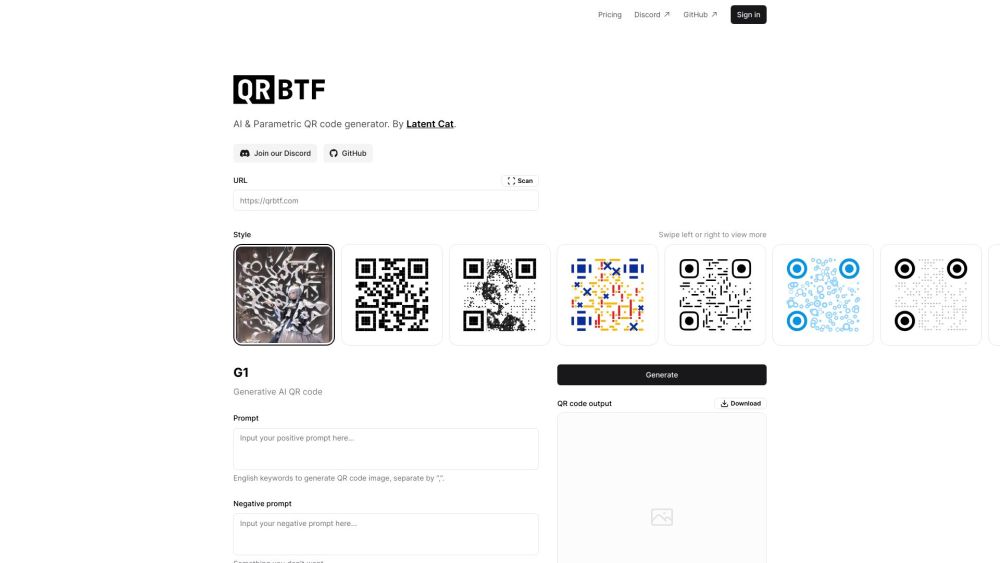
Introducing the ultimate AI-powered QR code generator—your first choice for creating stunning, high-quality QR codes effortlessly! Enhance your marketing strategy and engage your audience with our innovative tool designed to meet all your QR code needs. Try it today and experience the ease and effectiveness for yourself!
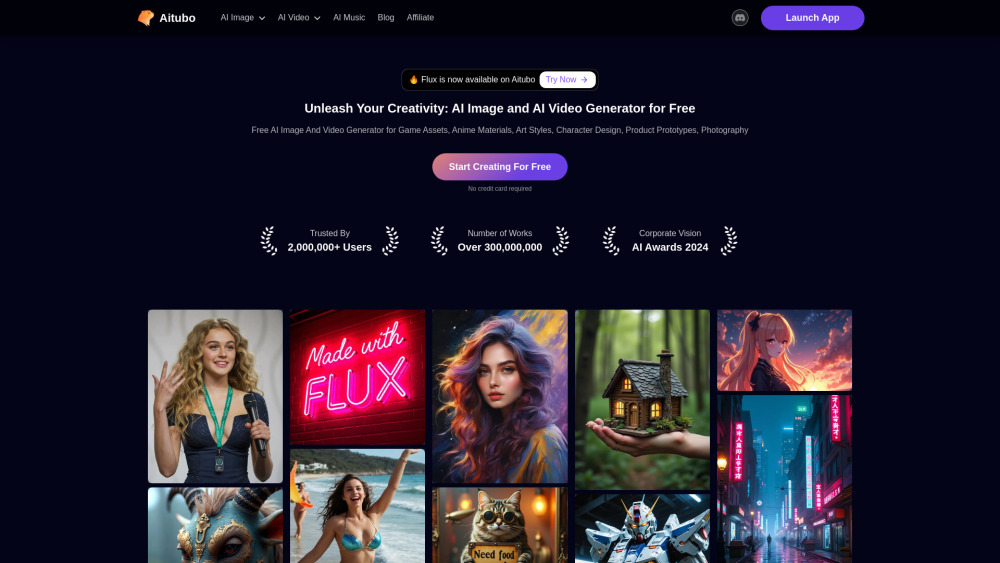
Unlock the power of AI with our cutting-edge image and video generator that transforms your text and images into stunning visual content. Enhance your creative projects effortlessly by harnessing advanced artificial intelligence technology designed for seamless content creation. Experience a new level of creativity today!

Typed is a powerful collaborative document tool that unites scattered documents, streamlines teamwork, and boosts research and productivity for users.
Find AI tools in YBX
Related Articles
Refresh Articles