Anthropic Researchers Discover AI Models Can Be Trained to Deceive Users
Most people like
Explore the transformative capabilities of our AI-powered dropshipping store platform. Designed to streamline your online retail operations, this innovative solution empowers entrepreneurs to effortlessly manage product sourcing, customer interactions, and inventory. Leverage cutting-edge technology to maximize efficiency, reduce overhead, and enhance the shopping experience for your customers. Embrace the future of e-commerce and watch your business thrive with our intuitive, user-friendly platform.
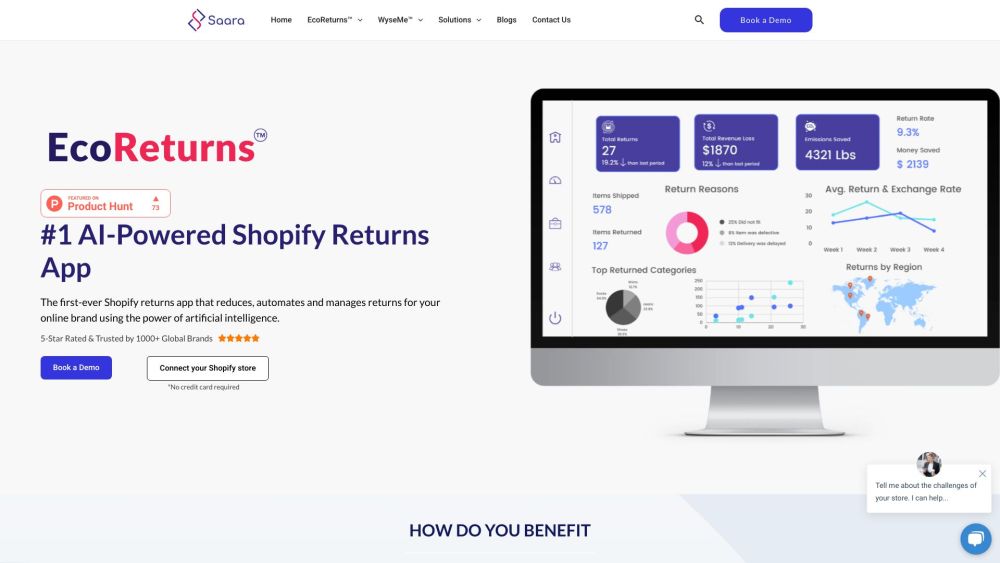
Saara is an innovative AI software designed to enhance returns management and boost customer satisfaction in the e-commerce sector. By streamlining processes and providing intelligent insights, Saara empowers online retailers to optimize their returns strategy, ensuring a seamless shopping experience for their customers.
Discover our free online AI-powered mind mapping tool, designed to enhance your brainstorming sessions and boost creativity. With intuitive features and advanced algorithms, this tool helps you visually organize your thoughts and ideas effortlessly. Whether you’re planning a project, outlining a story, or studying complex topics, our mind mapping tool streamlines your process and transforms chaotic thoughts into structured, actionable plans. Unlock the power of your imagination and elevate your productivity with our easy-to-use, AI-driven platform.

Find AI tools in YBX
Related Articles
Refresh Articles