"Apple, NVIDIA, and Anthropic Allegedly Used YouTube Transcripts Without Consent for AI Model Training"
Most people like
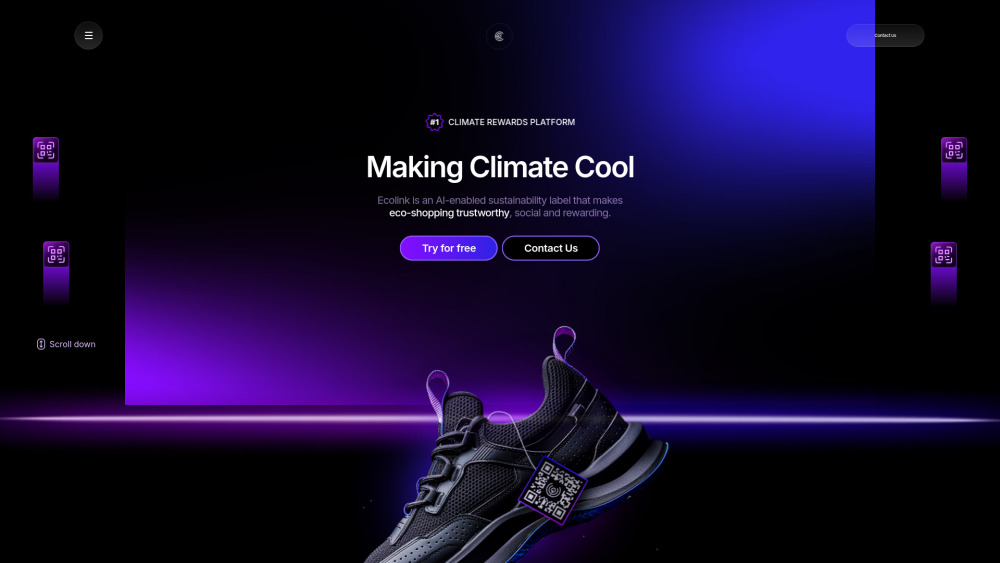
Introducing an innovative AI and blockchain sustainability platform designed to revolutionize how we approach environmental stewardship. By harnessing the power of artificial intelligence and blockchain technology, this platform aims to enhance transparency, increase efficiency, and promote sustainable practices across various industries. Join us in transforming the future of sustainability through cutting-edge technology.
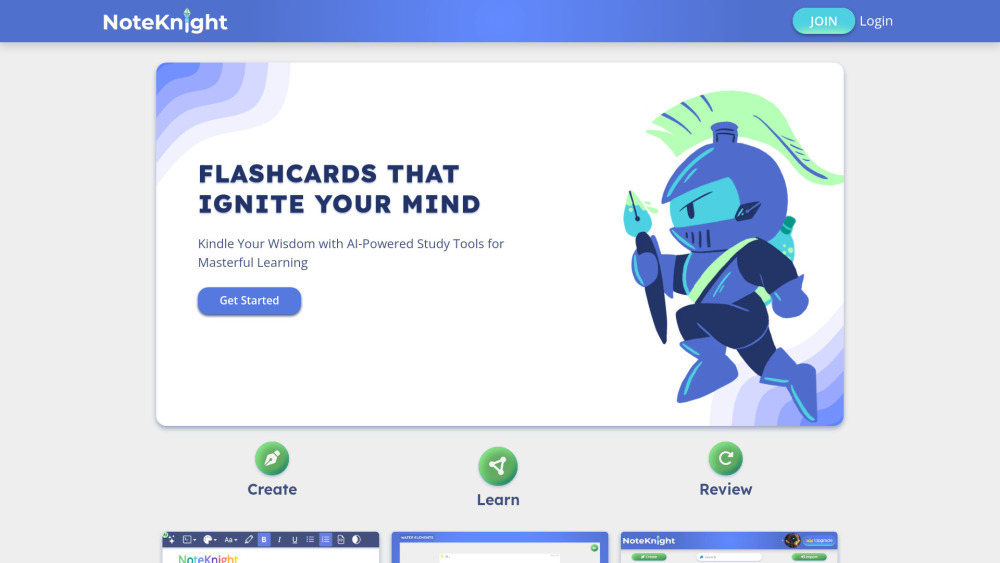
Transform your studying experience with our advanced flashcard maker, equipped with cutting-edge AI study tools. Create, customize, and optimize your study sessions effortlessly while leveraging intelligent algorithms to enhance retention and understanding. Embrace a smarter way to learn and master new material with our innovative platform.
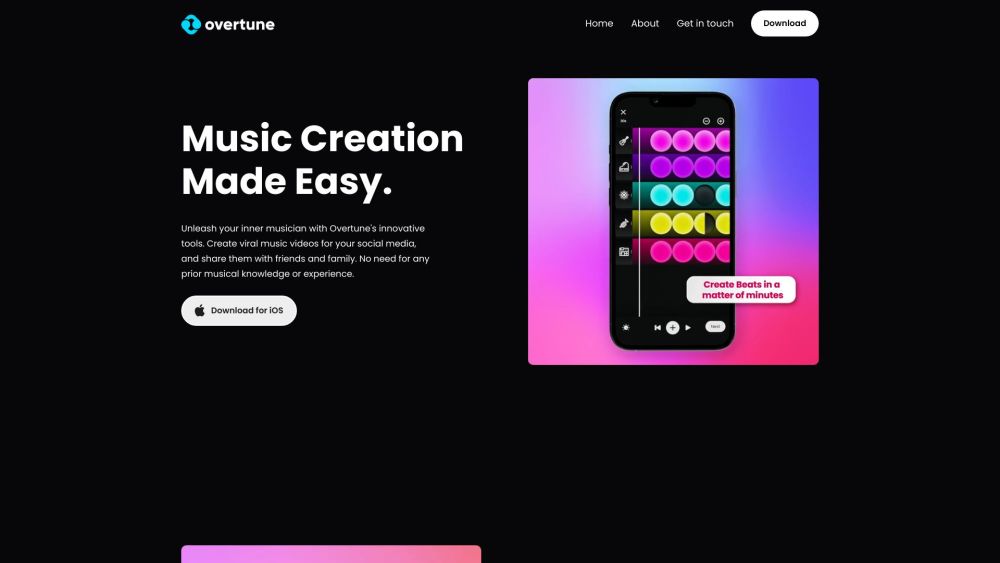
Overtune is an intuitive platform designed for effortless music creation, allowing users to produce high-quality tracks in no time.
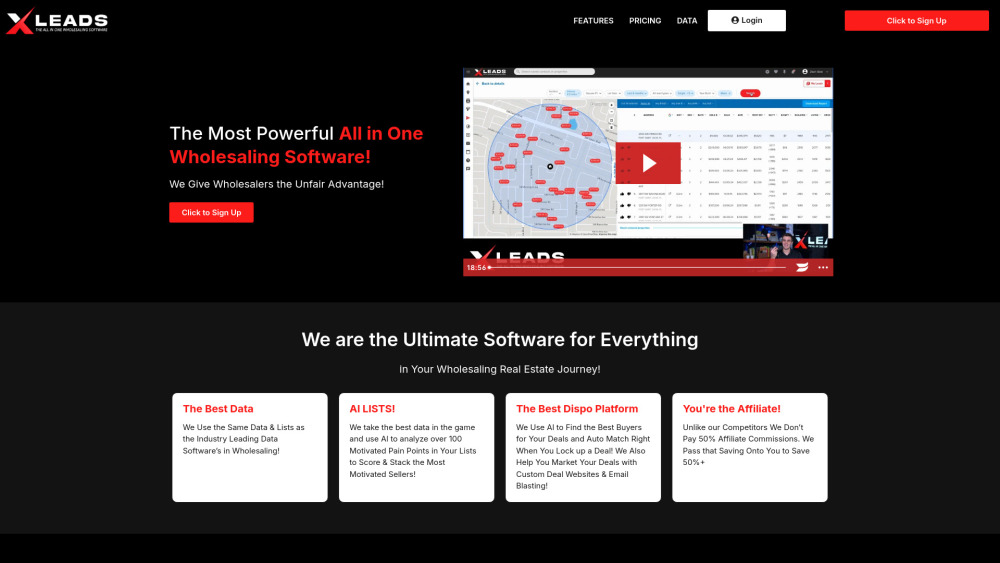
Find AI tools in YBX
Related Articles


Refresh Articles