Dou Xiaoman and Harbin Institute of Technology Develop Adaptive Pruning Algorithm to Enhance Computational Efficiency of Multimodal Large Models
Most people like

Introducing an intelligent assistant equipped with limitless memory capabilities. This advanced tool not only remembers everything but also enhances your productivity and efficiency, transforming the way you manage tasks and information. Discover how this powerful resource can revolutionize your daily routines and keep your life organized effortlessly.
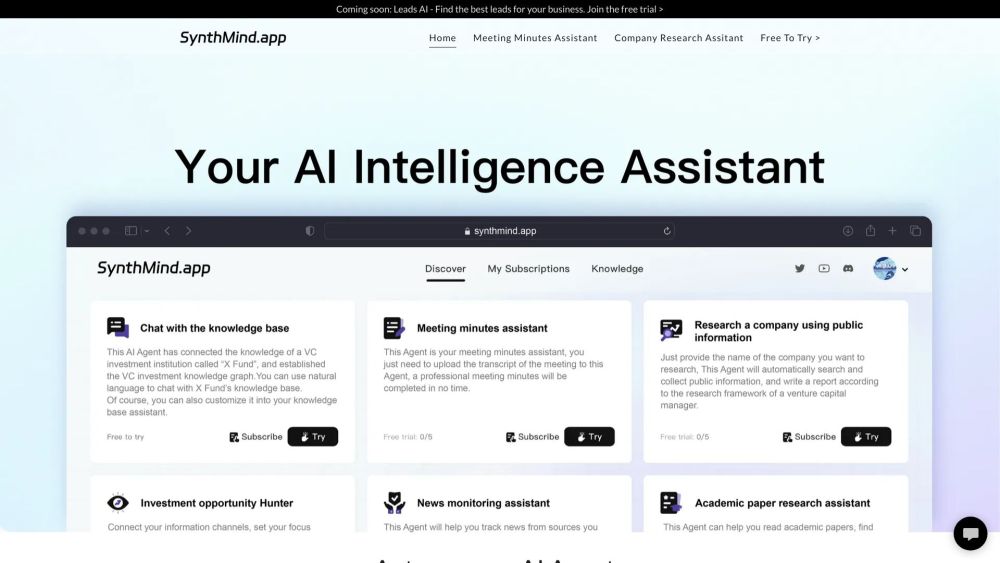
In today's fast-paced world, access to timely and accurate information is crucial for decision-making. Our AI-powered instant research reports deliver comprehensive insights rapidly, empowering businesses and individuals to stay ahead of the competition. By harnessing the capabilities of artificial intelligence, we provide tailored research that enhances your understanding of complex topics, enabling you to make informed choices effortlessly. Dive into a world of rapid research and experience the future of information gathering today!
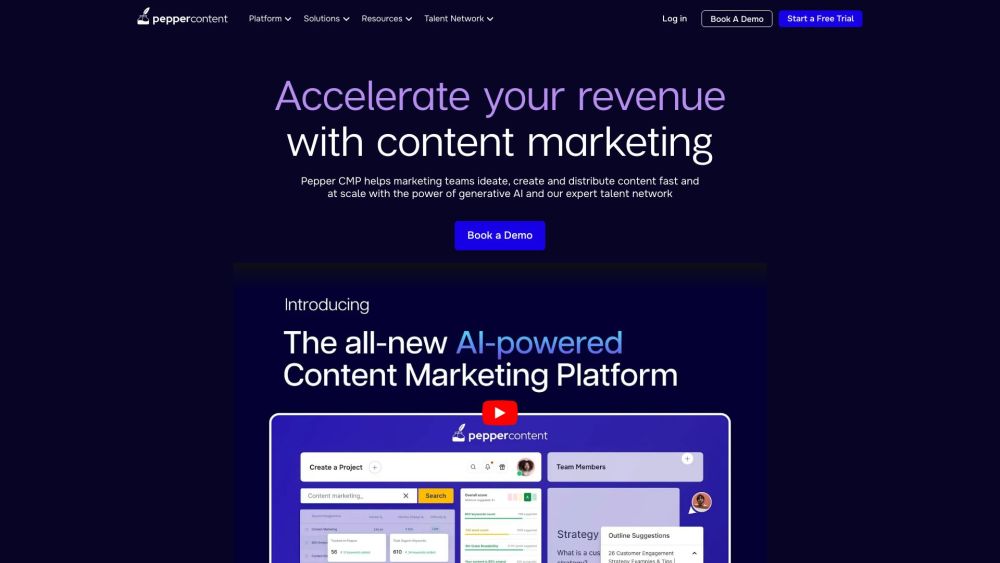
Introducing an AI-Powered Content Marketing Platform
Unlock the potential of your marketing strategy with our cutting-edge AI-driven content marketing platform. Designed to streamline your content creation and distribution, our platform harnesses the power of artificial intelligence to deliver engaging and relevant content tailored to your audience. Transform how you connect with customers, boost your brand visibility, and drive conversions effortlessly. Discover the future of content marketing today!
Introducing the ultimate camera for team sports enthusiasts. Whether you're capturing breathtaking game moments or analyzing performance, this camera is designed to bring your sports experience to the next level. With advanced features and user-friendly technology, it's the perfect tool for athletes, coaches, and fans alike.
Find AI tools in YBX
