Google Researchers Utilize Your Mannequin Challenge Videos to Train AI Models
Most people like
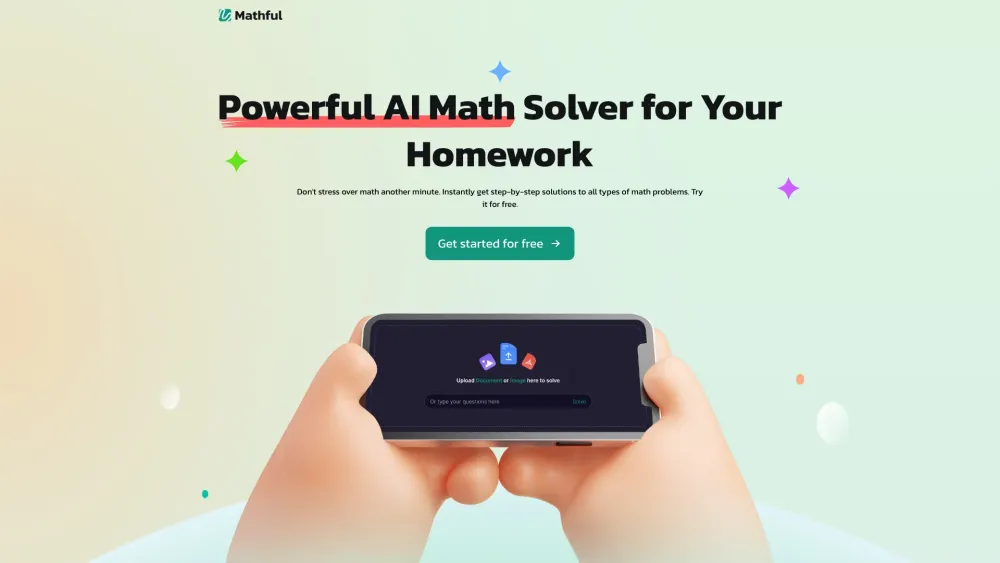
Unlock the power of mathematics with our Advanced Math AI Solver, designed to assist users of all levels in solving complex equations and understanding intricate concepts. Whether you're a student aiming to enhance your problem-solving skills or a professional seeking quick solutions, our cutting-edge AI technology provides step-by-step explanations, making even the toughest math challenges manageable. Explore the future of learning with our versatile and user-friendly tool, tailored to elevate your mathematical proficiency and boost your confidence in tackling any math problem.
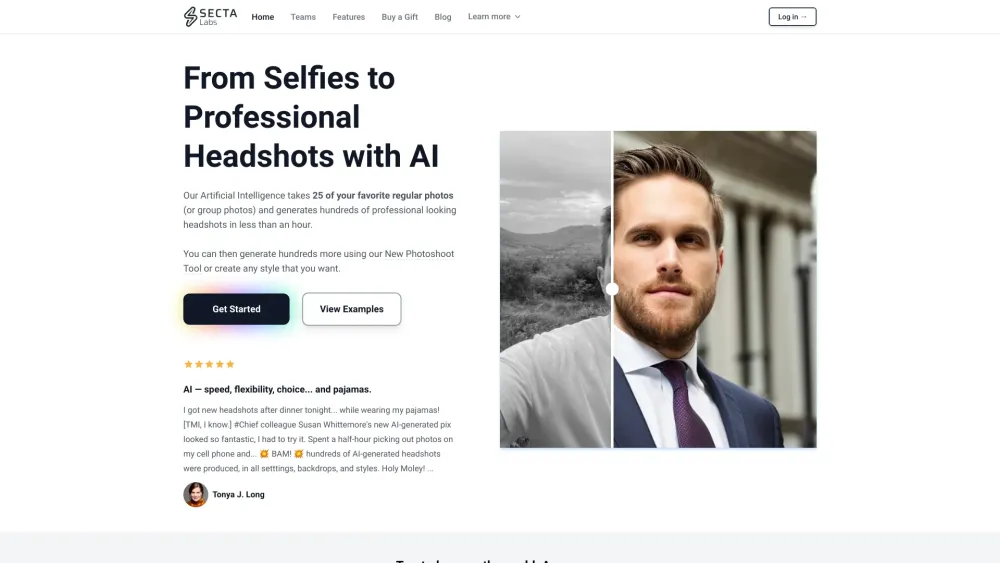
In today's digital world, a strong first impression is crucial. AI-generated professional headshots not only enhance your online presence but also convey professionalism and approachability. Utilizing advanced artificial intelligence technology, these headshots are crafted to meet the unique style and branding needs of individuals and businesses alike. Discover how embracing AI-generated imagery can transform your personal and professional brand, setting you apart in a competitive landscape.
Lalamu Studio provides innovative tools and resources designed specifically for artists and designers, empowering their creative journeys.
Find AI tools in YBX
Related Articles


Refresh Articles