Introducing GPT-4V(ision): A Comprehensive 166-Page Guide from Microsoft's Multimodal AI Model!
Most people like
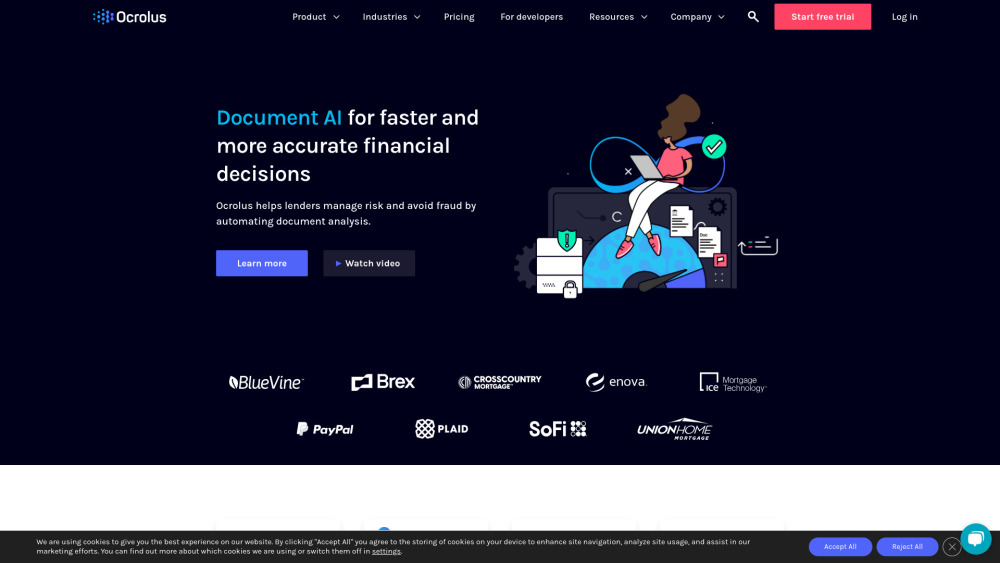
In today’s fast-paced business environment, managing financial documents can be an overwhelming task. Financial document automation software offers a solution by streamlining the creation, organization, and processing of financial documents. This innovative technology helps businesses improve efficiency, reduce human error, and ensure compliance, making it an essential tool for financial professionals. Discover how implementing financial document automation software can transform your financial operations and boost productivity.
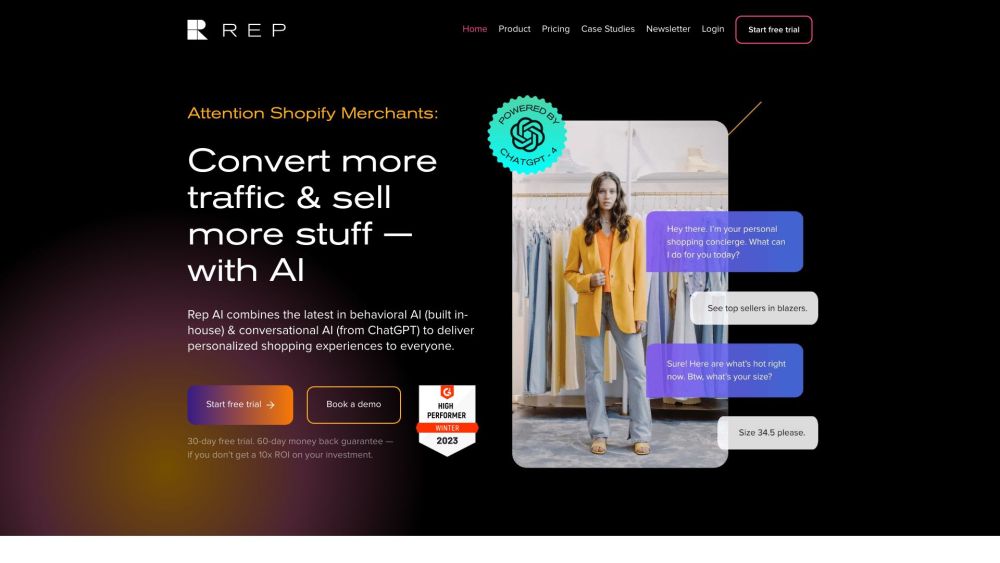
Introducing Shopify's Rep AI Home—a cutting-edge AI chatbot designed to enhance your online shopping experience. With its ability to provide tailored assistance, this innovative tool ensures that customers receive personalized recommendations and support, making shopping more engaging and efficient than ever.
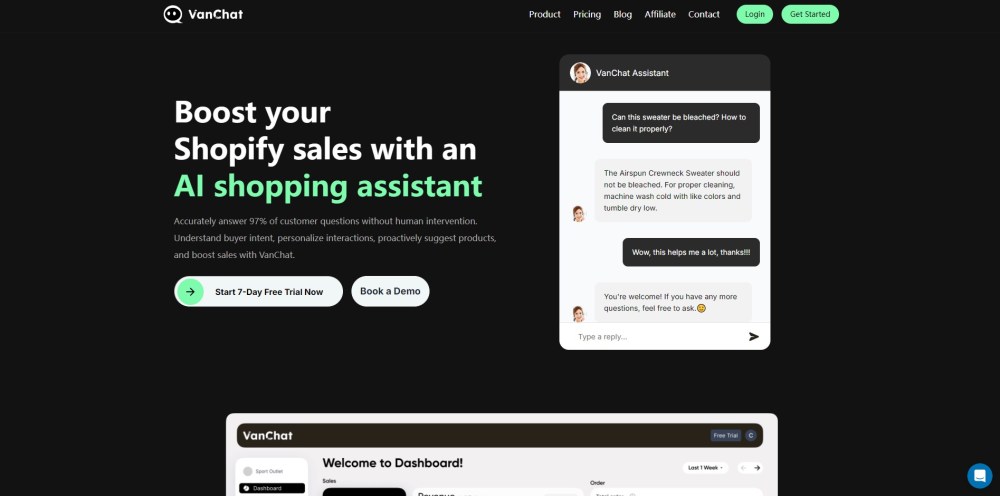
Discover how an AI shopping assistant for Shopify can transform customer interactions, driving engagement and boosting sales. By leveraging advanced technology, this innovative tool enhances the shopping experience, making it seamless and personalized for every user. Elevate your Shopify store today with an intelligent assistant that understands customer needs.

In an innovative twist on traditional beauty pageants, an AI beauty contest is now being assessed by robots. This groundbreaking event merges technology and aesthetics, challenging our perceptions of beauty in the digital realm. By utilizing advanced algorithms and artificial intelligence, the contest pushes the boundaries of creativity and explores what beauty means in a world increasingly influenced by automation and machine learning.
Find AI tools in YBX
Related Articles


Refresh Articles