OpenAI President Unveils First Image Created by GPT-4o
Most people like
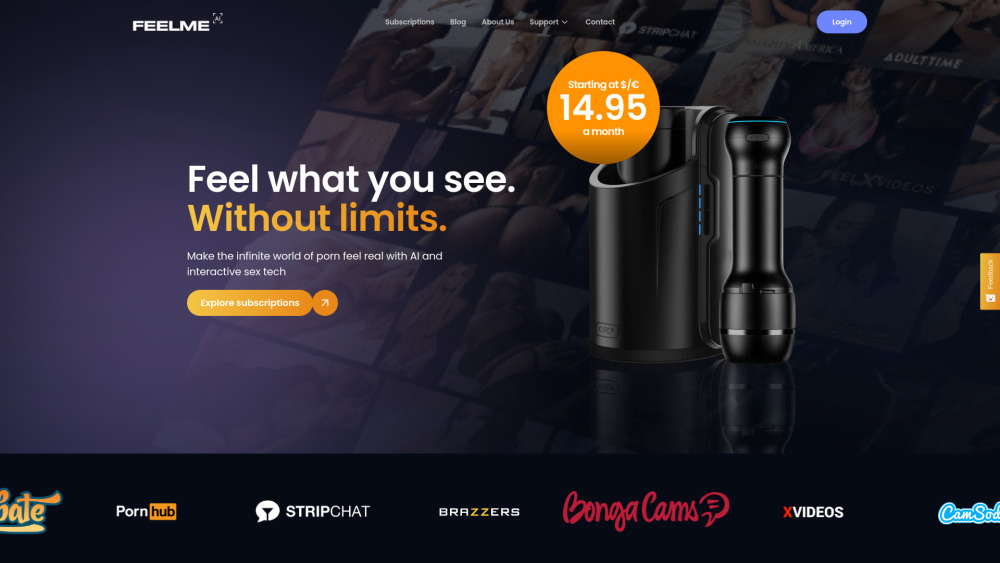
Discover a cutting-edge interactive adult entertainment platform that transforms the way you engage with content. By integrating immersive features and user-driven experiences, we enhance pleasure and satisfaction in a unique way. Explore how our innovative approach redefines adult entertainment, making it more personalized and engaging than ever before.
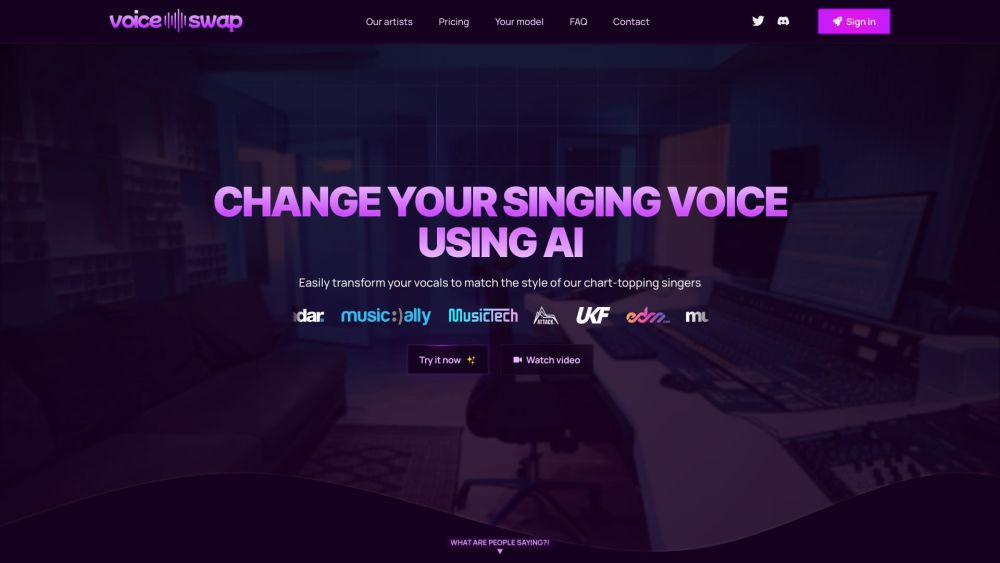
Introducing Voice-Swap: an innovative AI tool designed for seamless voice transformation. Perfect for remote collaborations and delivering lifelike demos, Voice-Swap empowers users to enhance their projects with stunning audio versatility.

Welcome to our AI insights platform, designed specifically for creators and businesses looking to harness the power of artificial intelligence. Our platform provides valuable data-driven insights that empower users to enhance creativity, improve decision-making, and drive growth. Discover how AI can transform your projects and strategies, paving the way for success in today's competitive landscape. Explore our features to unlock your full potential!
Discover the power of engaging AI conversations and seamless task automation. Unlock the potential of advanced AI to enhance communication while streamlining your workflows for increased productivity.
Find AI tools in YBX
Related Articles
Refresh Articles