UK AI Safety Institute Uncovers Vulnerabilities in Major LLMs with Simple Jailbreaking Techniques
Most people like

In today's digital landscape, AI chat-commerce is revolutionizing the way users interact with brands. By seamlessly integrating artificial intelligence into chat solutions, businesses can create engaging and personalized shopping experiences that resonate with customers. This innovative approach not only enhances user satisfaction but also drives conversions, making it essential for brands looking to stay competitive and foster deep connections with their audience.
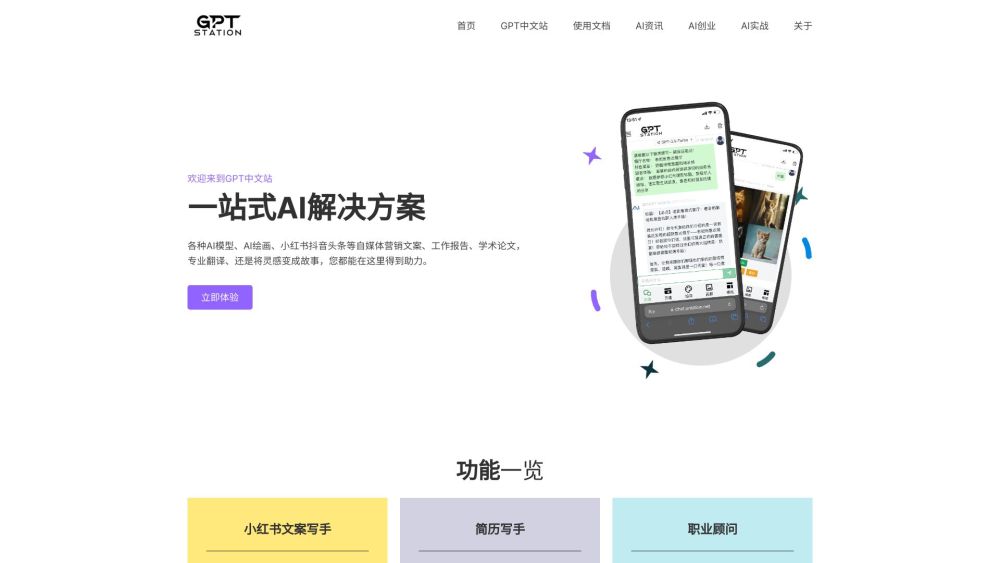
Discover a versatile AI platform designed for copywriting, translation, and various other tasks. This powerful tool enhances creativity and efficiency, making it an essential resource for content creators, marketers, and businesses alike. Unleash the potential of AI to transform your writing experience today!
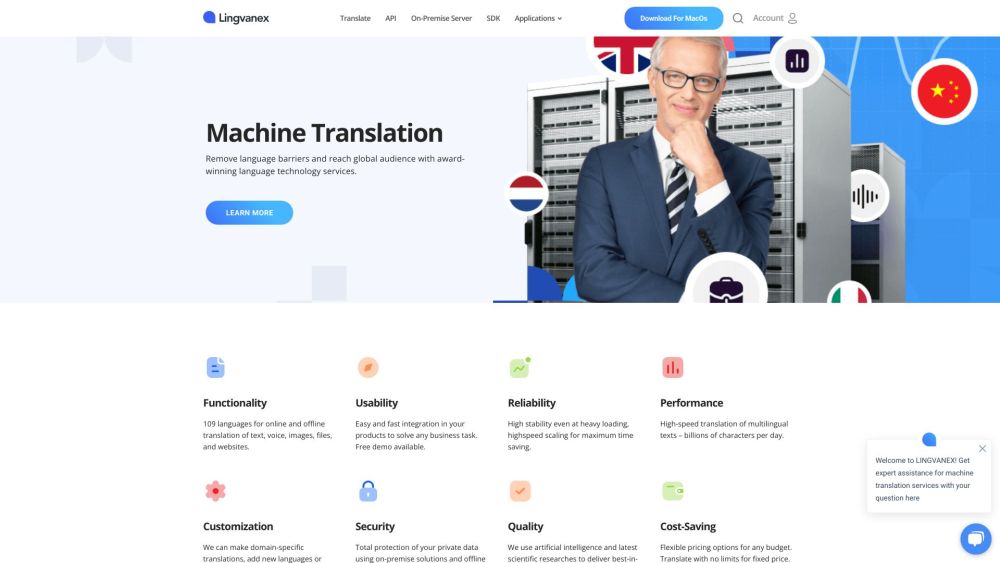
Lingvanex provides a variety of advanced translation tools powered by neural machine translation, designed to boost productivity and streamline communication.
Find AI tools in YBX
