Why Writer's Palmyra LLM is the Powerful AI Model Transforming Enterprises
Most people like
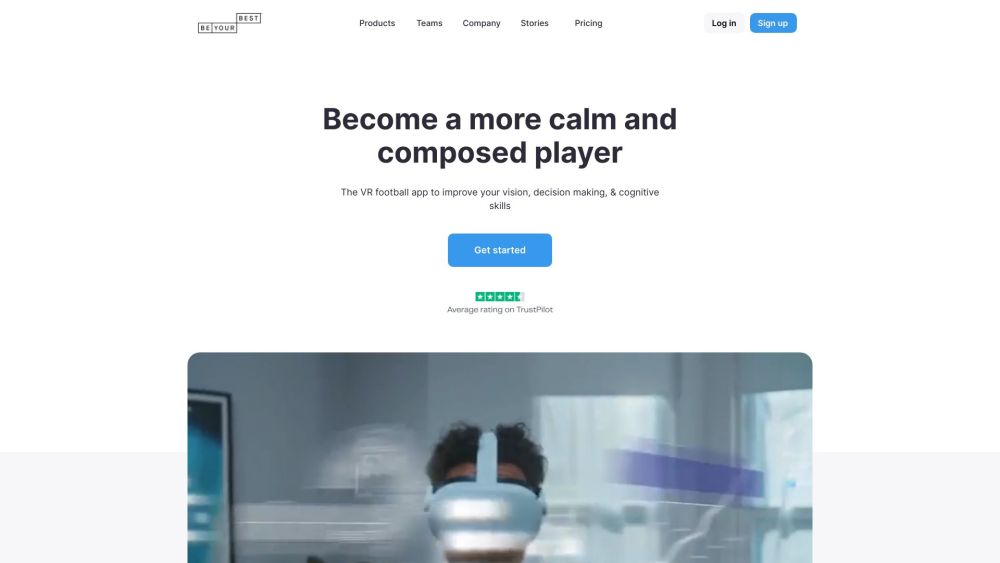
Enhance your vision and decision-making skills. Take your performance to the next level.
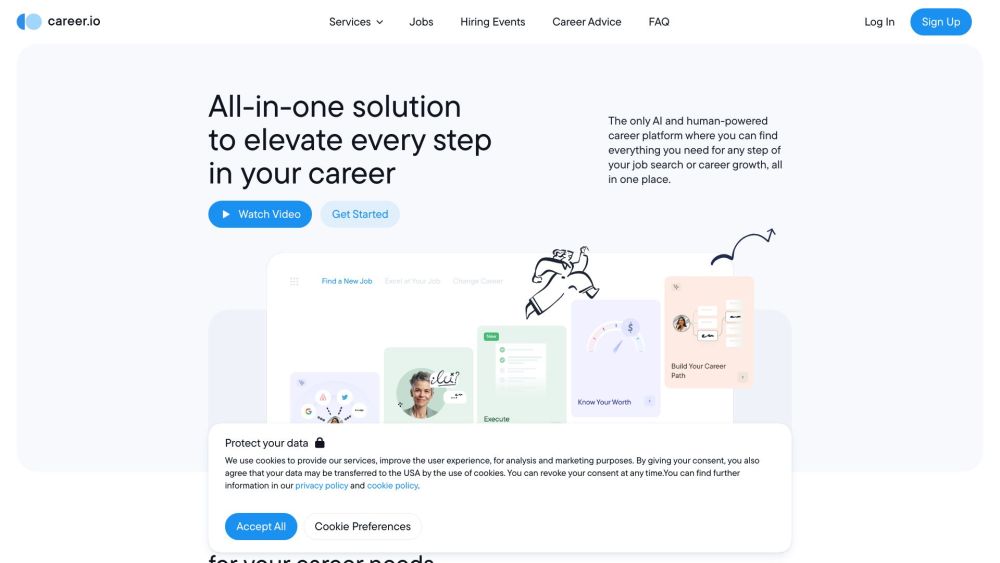
Unlock Your Career Potential with Our AI-Powered Career Services Platform
Experience unparalleled support on your professional journey with our innovative AI-driven career services platform. Designed to enhance your success, we provide personalized resources and expert guidance tailored to your unique career goals. Take the first step toward achieving your aspirations today!
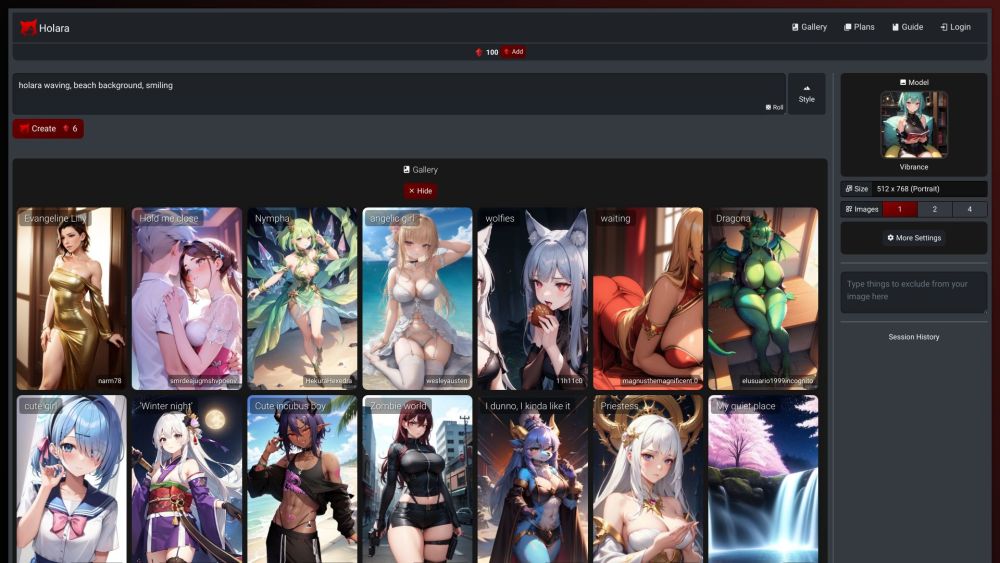
Are you an anime enthusiast or an aspiring artist looking to bring your creative visions to life? Our cutting-edge AI platform offers an innovative way to generate breathtaking anime artwork effortlessly. With a user-friendly interface and advanced algorithms, you can transform your ideas into stunning visuals in no time. Join a community of creators and unleash your imagination with our powerful tools designed specifically for anime art. Embrace the future of creativity with our AI-driven platform today!
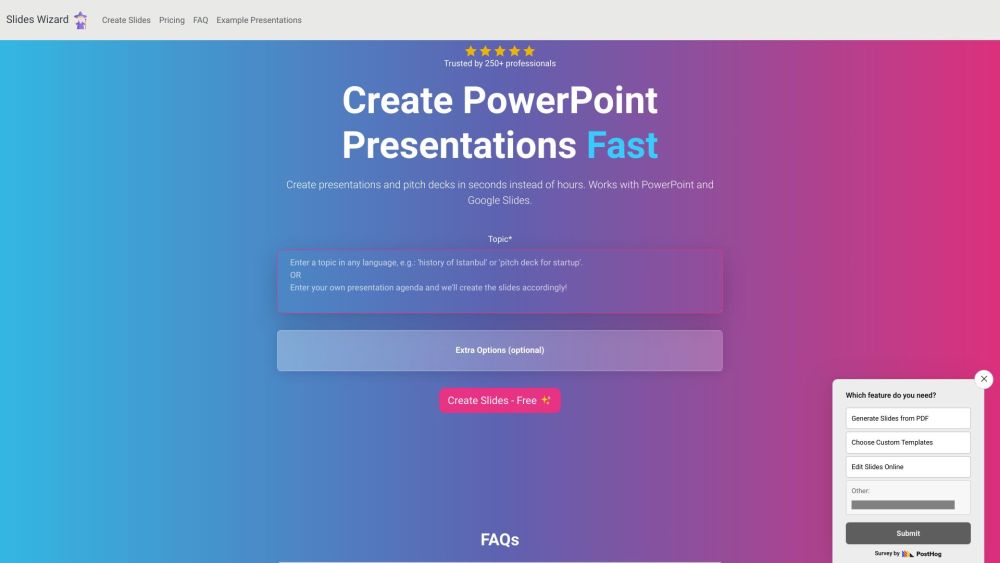
Create Stunning Presentations in Seconds
In today’s fast-paced world, the ability to generate captivating presentations quickly is essential for professionals and students alike. With cutting-edge tools at your fingertips, you can craft eye-catching slides in mere seconds, allowing you to focus on delivering your message effectively. Whether you’re preparing for a business meeting, academic lecture, or creative pitch, our streamlined process empowers you to produce high-quality presentations effortlessly. Say goodbye to hours of design work and hello to instant presentation perfection!
Find AI tools in YBX
