أوبن أي آي ترد علنًا على دعوى حقوق الطبع والنشر المقدمة من صحيفة نيويورك تايمز: تدّعي أنها "لا تستند إلى أساس".
Most people like
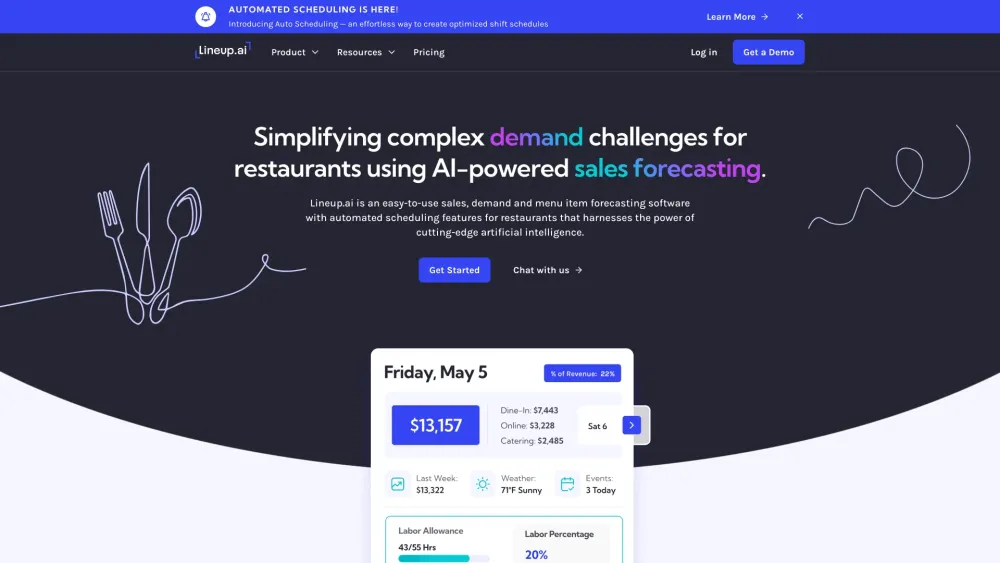
عزز كفاءة مطعمك من خلال برمجيات التنبؤ المتطورة المدعومة بالذكاء الاصطناعي. قم بتبسيط العمليات، وتحسين إدارة المخزون، وزيادة رضا العملاء من خلال الاستفادة من قوة الذكاء الاصطناعي. اكتشف كيف يمكن للرؤى المدفوعة بالذكاء الاصطناعي تحويل منشأتك الغذائية إلى آلة متكاملة، جاهزة للتكيف مع اتجاهات السوق وزيادة الربحية.
في المشهد الرقمي اليوم، يتزايد الطلب بسرعة على بنية تحتية سحابية قوية. منصتنا المدعومة بالذكاء الاصطناعي لتصميم البنية التحتية السحابية تستفيد من خوارزميات متقدمة لتبسيط عملية التطوير، مما يمكّن الشركات من إنشاء حلول سحابية قابلة للتوسع، وكفؤة، وآمنة. من خلال استغلال الذكاء الاصطناعي، نعمل على تمكين المنظمات من تحسين بنيتها التحتية، وتقليل التكاليف، وتعزيز الأداء، مما يضمن لها البقاء في الصدارة في سوق يتسم بتنافسية متزايدة. اكتشف كيف يمكن لنهجنا المدفوع بالذكاء الاصطناعي أن يحول استراتيجياتك السحابية للمستقبل.
هل تواجه صعوبة في تنظيم مواد دراستك أو تبحث عن طرق مبتكرة للتحضير للامتحانات؟ مساعدنا الذكي للدراسة موجود لمساعدتك! هذه الأداة الذكية لا تعمل فقط على تنظيم موارد دراستك بكفاءة، بل تتيح لك أيضًا إنشاء اختبارات مخصصة لتعزيز تعلمك. استمتع بطريقة أكثر ذكاءً للدراسة وحسن أداءك في الامتحانات مع هذا الحل المتطور المدعوم بالذكاء الاصطناعي.

شارك في محادثات حيوية مع نماذج الذكاء الاصطناعي المفضلة لديك، بما في ذلك LLaMA و Alpaca و GPT4All، على LlamaChat. استمتع بتفاعلات بديهية واستكشف إمكانيات هذه الروبوتات المتطورة اليوم!
Find AI tools in YBX
Related Articles
Refresh Articles