سابقا نوفا تطلق نموذج التركيب من 1 تريليون معلمة للذكاء الاصطناعي التوليدي في الشركات
Most people like

افتح قوة مساعد الكتابة الذكي الخاص بك، المصمم لتحسين تجربتك الكتابية. سواء كنت تكتب منشورات مدونة جذابة، مقالات مثيرة، أو قصص إبداعية، فإن هذه الأداة تبسط عملية الكتابة، تعزز الوضوح، وتزيد من الإنتاجية. وداعًا لانسداد الكتابة ومرحبًا بالإبداع السلس مع حليفك الذكي الشخصي، الذي يكون جاهزًا لمساعدتك في كل خطوة.
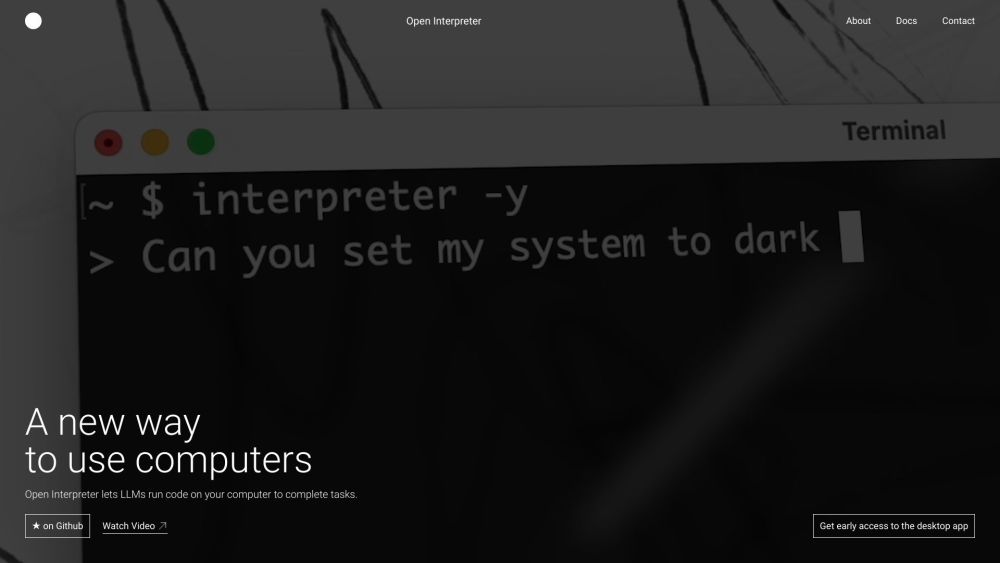
فتح تنفيذ الشيفرات وأتمتة المهام من خلال نماذج اللغة قد غيّر الطريقة التي نتفاعل بها مع التكنولوجيا. من خلال استغلال قوة الذكاء الاصطناعي المتقدم، تمكّن هذه النماذج من أتمتة سلسة، مما يبسط سير العمل ويعزز الإنتاجية. اكتشف كيف يمكنك الاستفادة من نماذج اللغة لتبسيط مهام البرمجة المعقدة وأتمتة العمليات كما لم يحدث من قبل.
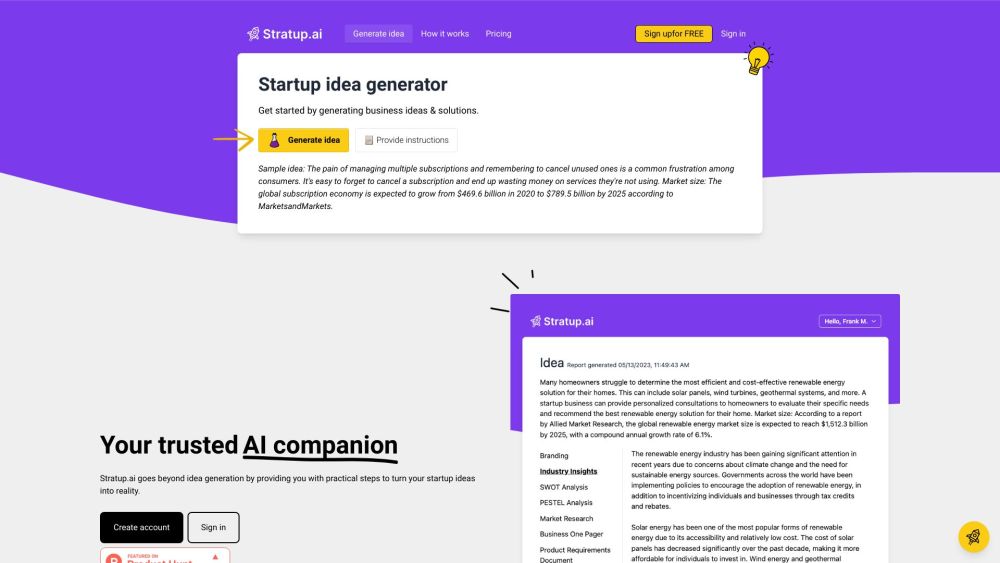
ستراتب.آي تستخدم قوة الذكاء الاصطناعي لتوليد أفكار مبتكرة للشركات الناشئة بسرعة كبيرة خلال ثوانٍ.

بيتش إن هاير هو برنامج مبتكر مدعوم بالذكاء الاصطناعي مصمم لتحسين عملية التوظيف من خلال أدوات وميزات متطورة. بفضل الأتمتة الذكية، يسهل بيتش إن هاير عملية التوظيف، ويعزز تقييم المرشحين، ويزيد من الكفاءة العامة لأرباب العمل.
Find AI tools in YBX
Related Articles
Refresh Articles