Anthropics Claude 3.5 Sonnet entdecken: KI-Enthusiasten sagen, „Das ist verrückt!“
Most people like
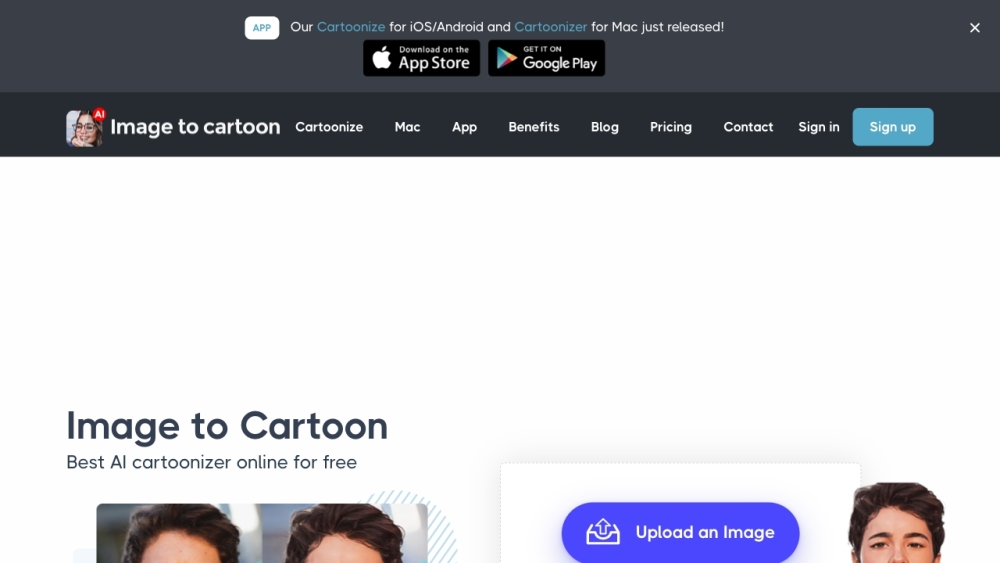
Verwandeln Sie Ihre Fotos mühelos in auffällige Cartoon-Avatare mit ImagetoCartoon!
Wir präsentieren unseren KI-gestützten virtuellen Mathe-Tutor, der speziell für Kinder im Alter von 5 bis 13 Jahren entwickelt wurde. Dieses innovative Werkzeug bietet personalisierte Lernerfahrungen und hilft jungen Lernenden, mathematische Konzepte auf ansprechende Weise zu verstehen. Mit interaktiven Lektionen, sofortigem Feedback und maßgeschneiderten Übungsaufgaben fördert unser KI-Tutor das Selbstbewusstsein und weckt die Begeisterung für Mathematik. Ob Ihr Kind Unterstützung bei grundlegenden Rechenarten oder fortgeschrittenen Themen benötigt, unser virtueller Tutor passt sich dem individuellen Lerntempo an und macht Mathe für jedes Kind angenehm und zugänglich.
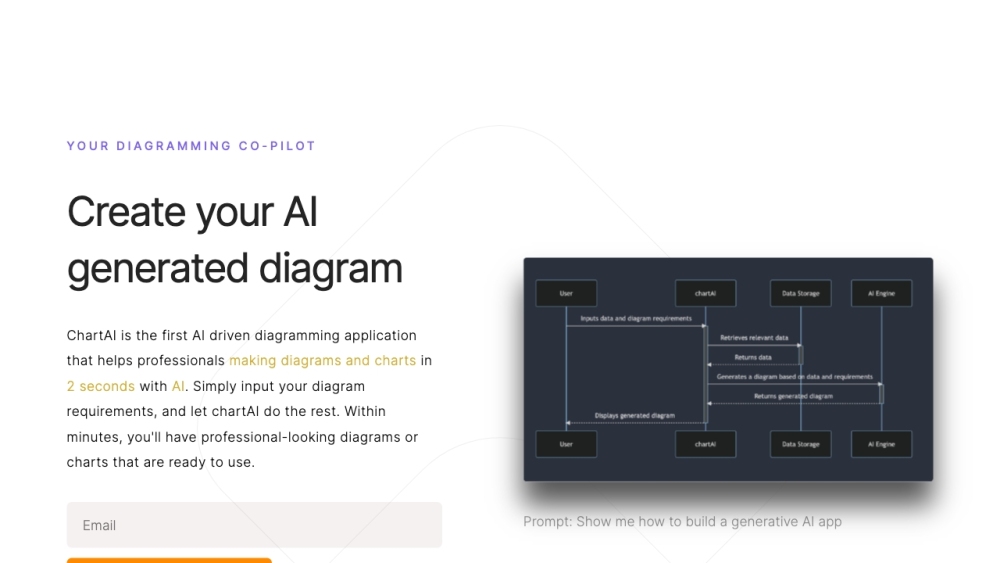
ChartAI nutzt die Leistungsfähigkeit von ChatGPT, um Nutzern bei der mühelosen Erstellung und Interpretation von Diagrammen und Grafiken zu helfen. Mit intuitiver Benutzerführung wandelt ChartAI komplexe Daten in visuell ansprechende und verständliche Darstellungen um, was Ihre Datenanalyse-Erfahrung verbessert.
Entdecken Sie den ultimativen personalisierten KI-Musikbegleiter, der Ihr Hörerlebnis verbessert. Dieses innovative Werkzeug passt Musikempfehlungen an Ihre einzigartigen Vorlieben an und erstellt einen individuellen Soundtrack nur für Sie. Mit fortschrittlichen Algorithmen lernt es aus Ihren Vorlieben und bietet kuratierte Wiedergabelisten, die mit Ihrer Stimmung harmonieren, sodass jeder Ton perfekt zu Ihrer Atmosphäre passt. Umarmen Sie die Zukunft der Musik mit einem KI-Begleiter, der sich mit Ihrer musikalischen Reise weiterentwickelt und jede Hörsession einzigartig macht.
Find AI tools in YBX
Related Articles
Refresh Articles