Apple, NVIDIA und Anthropic sollen angeblich YouTube-Transkripte ohne Zustimmung für das Training ihrer KI-Modelle verwendet haben.
Most people like
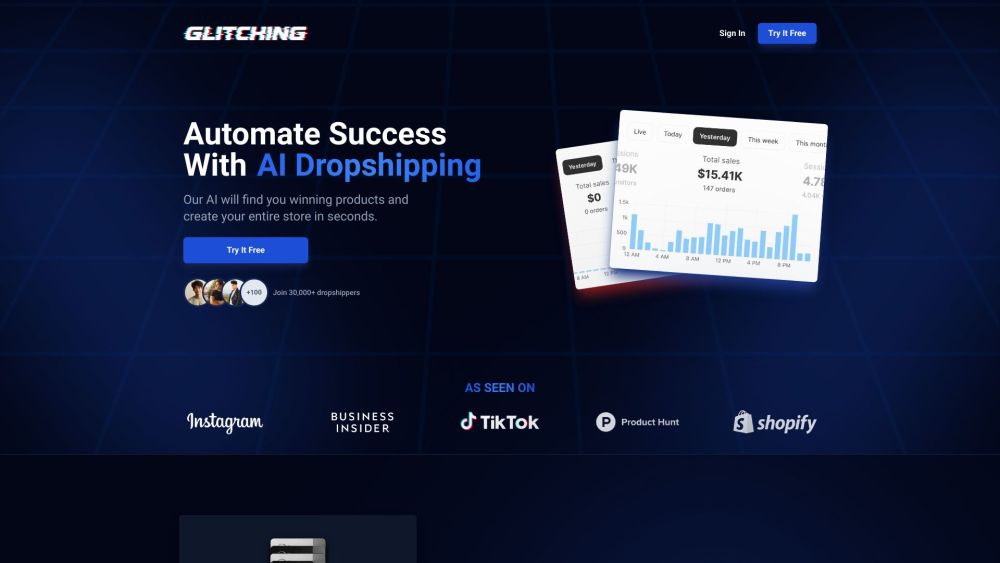
Entdecken Sie leistungsstarke Produkte und skalieren Sie Ihr Shopify-Dropshipping-Geschäft mühelos, um größeren Erfolg zu erzielen.

Entdecken Sie die besten ChatGPT-Alternativen für verbesserte KI-Chat-Funktionen! Führen Sie dynamische Gespräche und verbessern Sie Ihr Kommunikationserlebnis mit fortschrittlichen Chat-Lösungen, die auf Ihre Bedürfnisse zugeschnitten sind. Ob Sie innovative Funktionen oder überlegene Leistung suchen, erkunden Sie diese leistungsstarken Optionen für transformative Interaktionen.
Suchen Sie ein zuverlässiges KI-Umformulierungstool, um Texte mühelos neu zu schreiben? Egal, ob Sie Ihr Schreiben verbessern, Plagiate vermeiden oder komplexe Ideen vereinfachen möchten, unser fortschrittliches Tool wurde entwickelt, um Ihnen zu helfen. Mit nur wenigen Klicks können Sie Ihren Originaltext in eine neue Version verwandeln, die dieselbe Bedeutung beibehält, während sie Klarheit und Anziehungskraft verbessert. Entdecken Sie, wie unsere KI-gestützte Lösung Ihre Inhalte aufwerten und Ihr Schreiben zum Strahlen bringen kann.
Steigern Sie Ihre Fähigkeiten mit Echtzeit-Mock-Interviews und KI-gestütztem Feedback
Erleben Sie die Kraft von KI als Ihren persönlichen Coach mit unseren Echtzeit-Mock-Interviews und sofortigem Feedback. Unsere Plattform simuliert authentische Interview-Szenarien, die Ihnen helfen, sich effektiv vorzubereiten und maßgeschneiderte Einblicke zu erhalten, um Ihre Leistung zu verbessern. Machen Sie sich bereit, Ihre Interviewfähigkeiten zu transformieren und Ihr Selbstbewusstsein zu stärken!
Find AI tools in YBX
