Der GAIA Benchmark: KI der nächsten Generation meistert reale Herausforderungen
Most people like
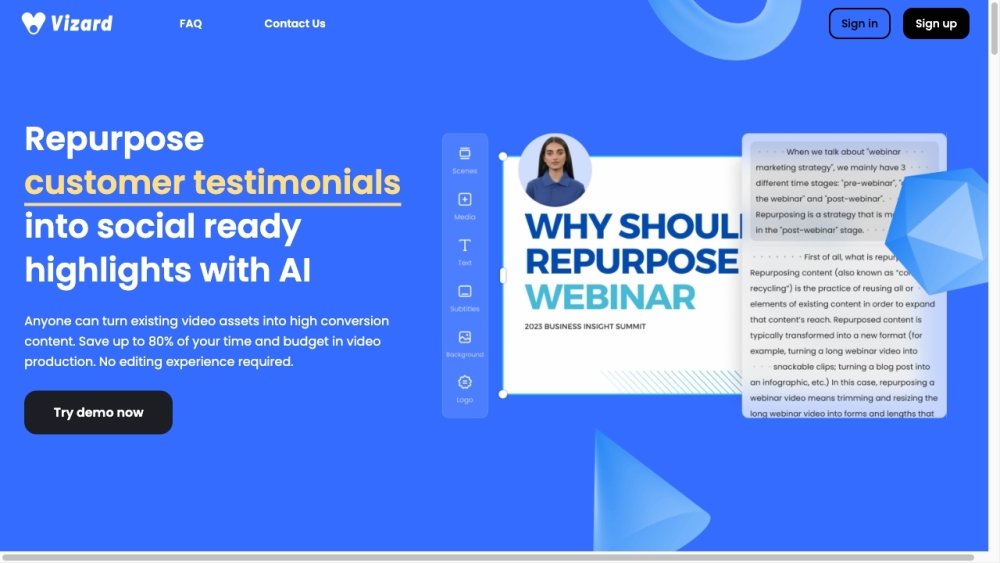
Vizard.ai ermöglicht es Nutzern, mühelos virale Social-Media-Videos mit fortschrittlicher KI-gestützter Bearbeitungstechnologie zu erstellen.
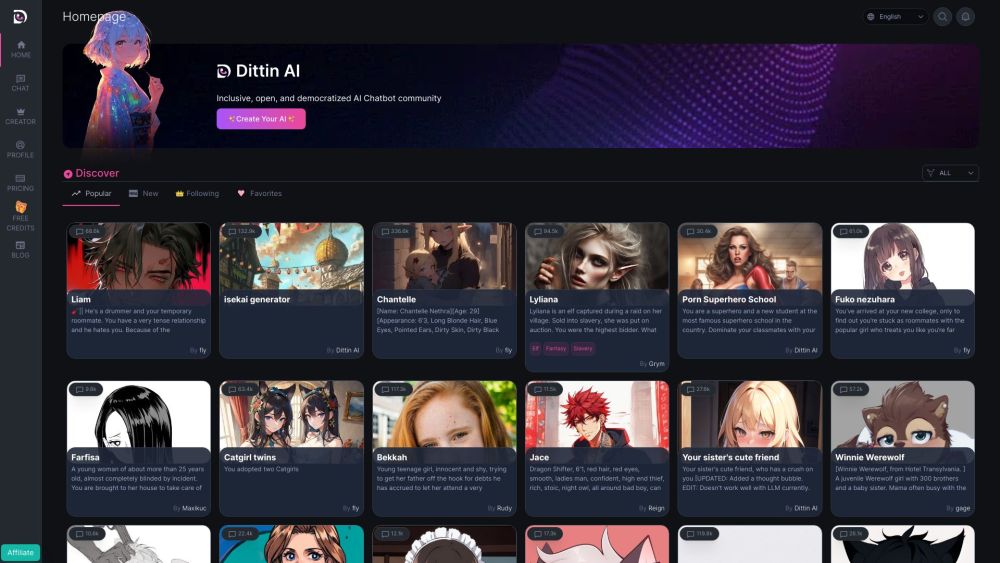
Willkommen in der Inclusive AI Chatbot Community, wo wir Innovatoren, Entwickler und Enthusiasten vereinen, die sich der Schaffung zugänglicher und benutzerfreundlicher KI-Chatbots widmen. Unsere Mission ist es, Zusammenarbeit zu fördern, Erkenntnisse zu teilen und bewährte Methoden zu unterstützen, die sicherstellen, dass Technologie allen dient, unabhängig von Herkunft oder Fähigkeit. Schließen Sie sich uns an, während wir die Zukunft der KI-Chatbots erkunden und dabei Inklusion betonen, um eine gerechtere digitale Welt für alle zu schaffen.
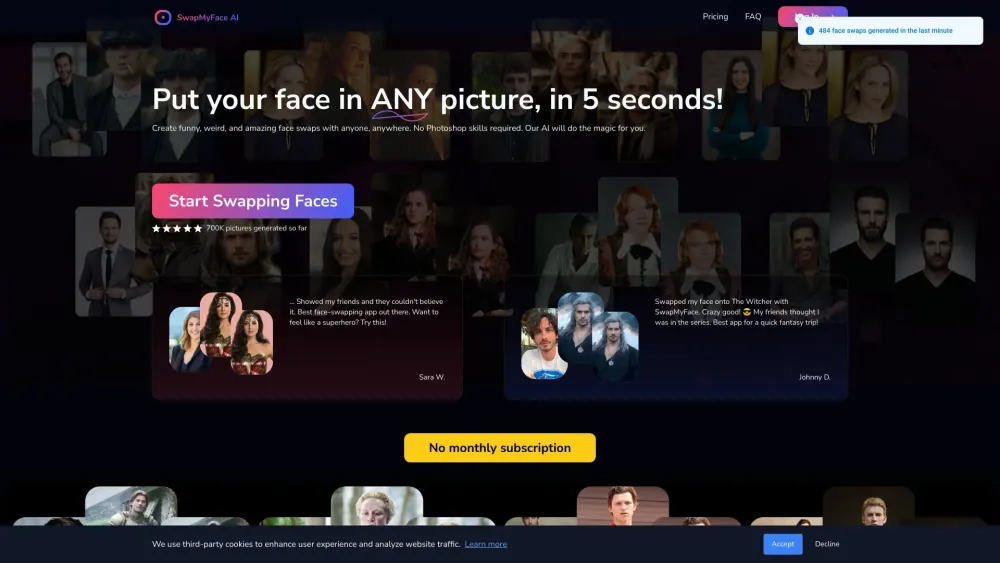
Entdecken Sie das ultimative KI-Gesichtstauschwerkzeug, das für die mühelose Transformation von Bildern entwickelt wurde. Diese innovative Technologie ermöglicht es Nutzern, Gesichter ganz einfach auszutauschen, was zu realistischen und nahtlosen Bearbeitungen führt. Egal, ob Sie lustige Memes erstellen, Ihre Social-Media-Beiträge aufwerten oder mit kreativen Projekten experimentieren, unser benutzerfreundliches Tool vereinfacht den Prozess und liefert beeindruckende Ergebnisse. Tauchen Sie ein und erleben Sie noch heute die Magie des KI-Gesichtstauschs!

In der heutigen visuell geprägten Welt sind hochwertige Bilder entscheidend, um die Aufmerksamkeit des Publikums zu gewinnen. Glücklicherweise revolutionieren Fortschritte in der künstlichen Intelligenz (KI) die Art und Weise, wie wir die Qualität von Videos und Fotos verbessern. Von automatischer Farbkorrektur bis hin zur Rauschreduzierung bieten diese innovativen Werkzeuge kreativen Fachleuten und Enthusiasten die Möglichkeit, ihre visuellen Inhalte mühelos zu verwandeln. Entdecken Sie, wie die Integration von KI-Technologie Ihre Bilder veredeln und beeindruckende Ergebnisse erzielen kann, die im heutigen Wettbewerb herausstechen.
Find AI tools in YBX
