Fragen zur Leistung des neuen Open-Source-KI-Leiters Reflection 70B, der des 'Betrugs' beschuldigt wird
Most people like
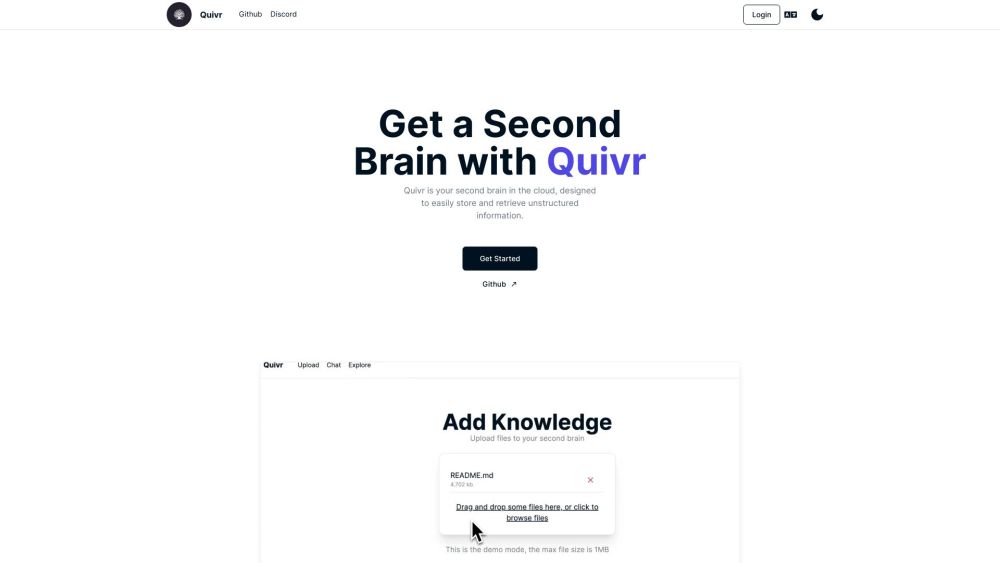
Präsentieren Sie Quivr, eine hochmoderne Cloud-Plattform, die für die effiziente Speicherung und den Abruf einer Vielzahl von Datentypen entwickelt wurde. Egal, ob Sie Texte, Bilder oder komplexe Datensätze verwalten, Quivr bietet eine nahtlose Lösung, die auf Ihre Datenverwaltungsbedürfnisse zugeschnitten ist. Erleben Sie heute mit Quivr unvergleichliche Zugänglichkeit und Organisation!
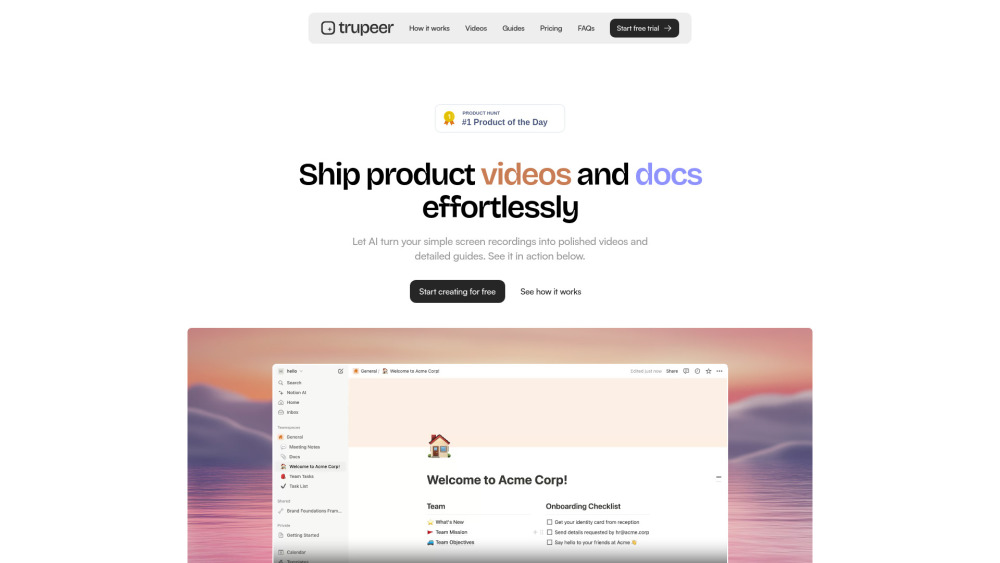
Revolutionieren Sie Ihr Produktmarketing mit unserer KI-gestützten Plattform, die Bildschirmaufnahmen in ansprechende Produktvideos und umfassende Dokumentationen verwandelt. Optimieren Sie Ihren Inhaltserstellungsprozess und steigern Sie die Zuschauerbindung wie nie zuvor.
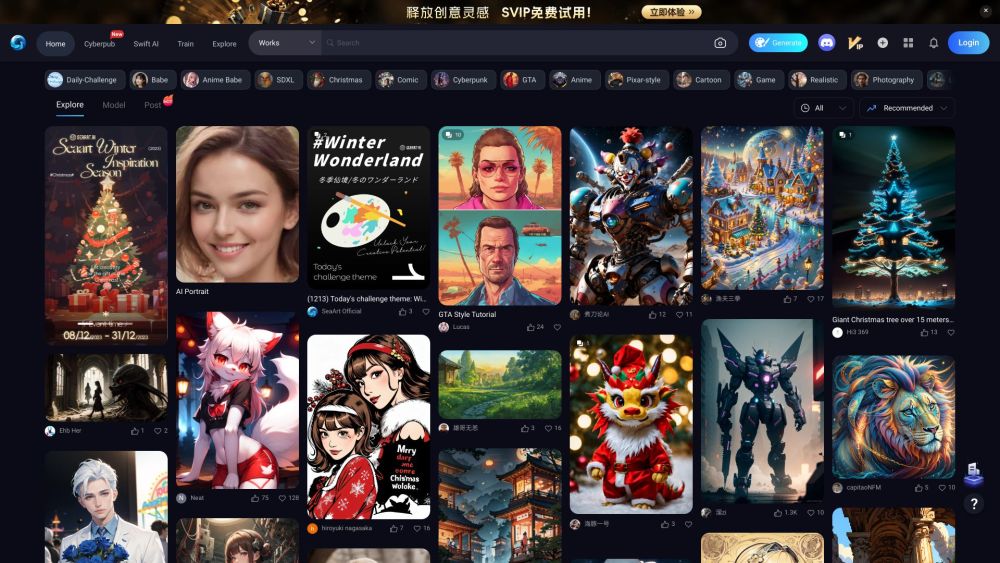
Entfesseln Sie die Kraft von KI-generierten Illustrationen
Entdecken Sie die spannende Welt der KI-Illustrationsgenerierung mit unserer innovativen Plattform. Hier treffen Kreativität und modernste Technologie aufeinander, sodass Nutzer mühelos beeindruckende Illustrationen erstellen können. Egal, ob Sie ein professioneller Künstler, ein Designer oder einfach nur jemand sind, der seine künstlerische Seite erkunden möchte – unsere KI-gesteuerten Werkzeuge bieten Ihnen unendliche Möglichkeiten, um Ihre Ideen zum Leben zu erwecken. Werden Sie noch heute Teil von uns und revolutionieren Sie Ihre visuelle Gestaltung!
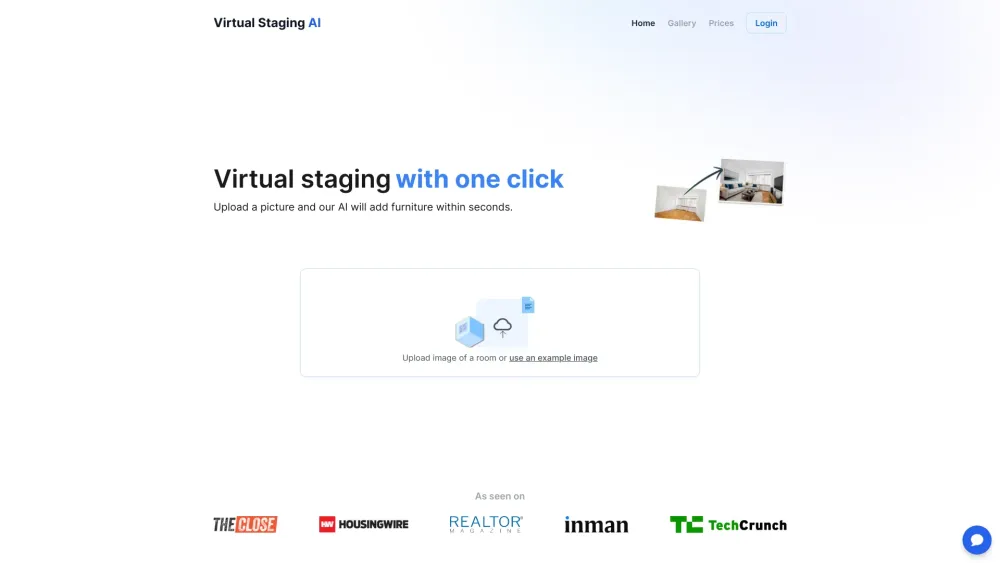
Transformieren Sie Ihre Immobilienanzeigen mit unserer KI-gestützten virtuelen Staging-App für Immobilienprofis
Entdecken Sie, wie unsere innovative, KI-gesteuerte virtuelle Staging-App Ihre Immobilienanzeigen aufwerten kann. Speziell für Immobilienprofis entwickelt, ermöglicht Ihnen dieses leistungsstarke Tool, atemberaubende, fotorealistische Visualisierungen zu erstellen, die potenzielle Käufer fesseln und die Attraktivität der Objekte steigern. Verbessern Sie Ihre Marketingstrategie und heben Sie sich in einem wettbewerbsintensiven Markt mit unserer zukunftsweisenden Technologie ab, die den Präsentationsprozess Ihrer Immobilien optimiert.
Find AI tools in YBX
